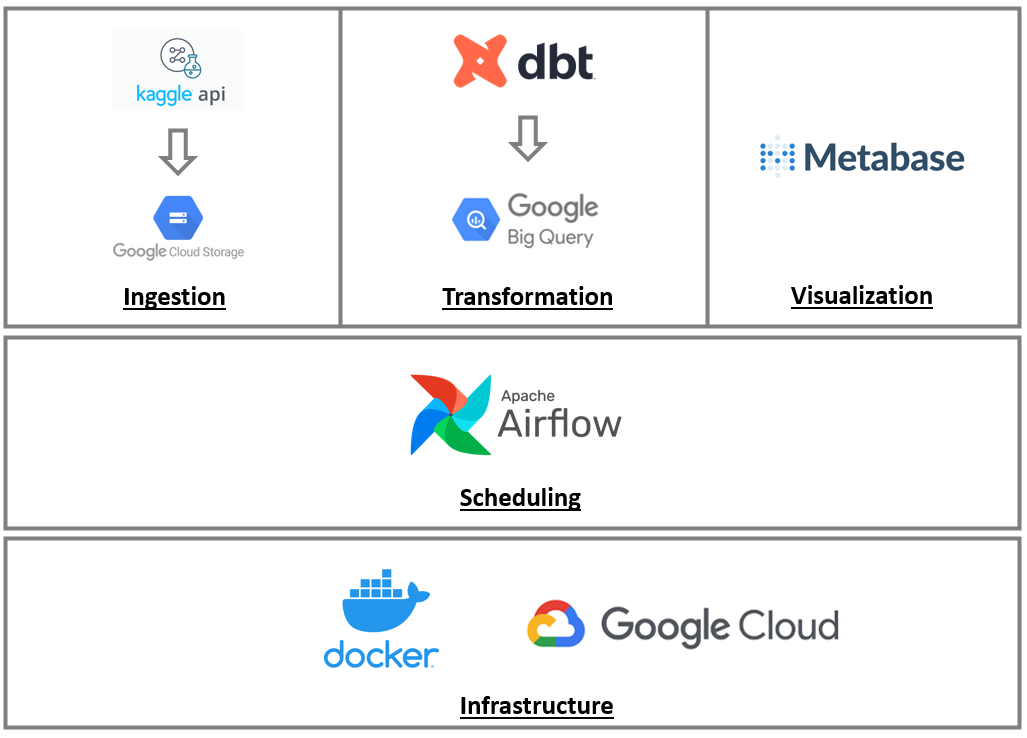
Twitter Real-time Word Processing
Real time word processing using Apache Spark (PySpark).
Overview
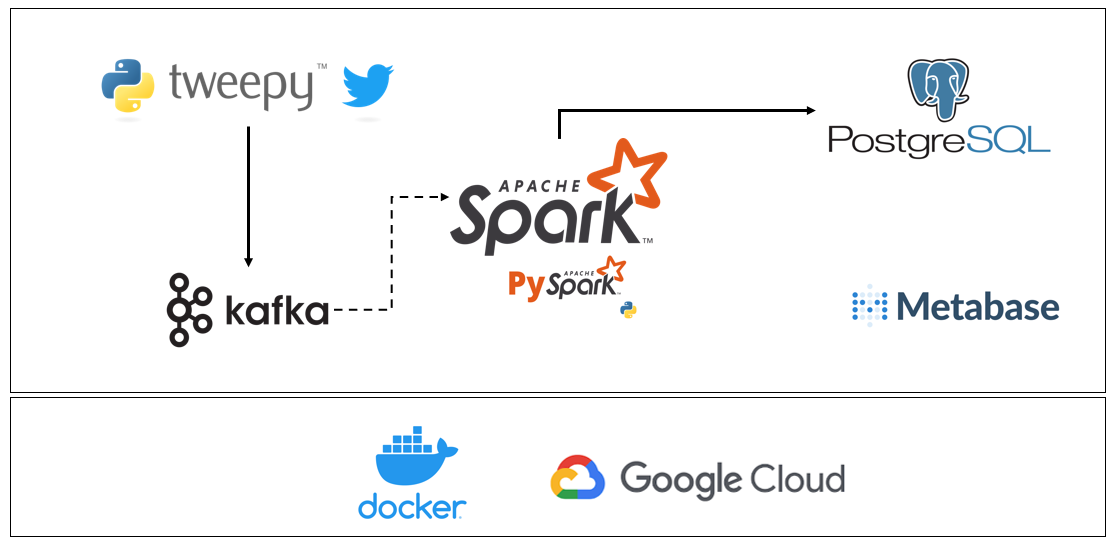
The main goal of this project was to do a little PoC and learn how real-time data processing works. When someone begins their journey in data engineering, they will usually start out with a similar project. What I did was use a much known API from Twitter. With the help of Tweepy I was able to gather the tweets of specific content based on the keywords stored on a Postgres database. Following this search, the Tweepy sent the tweets to a Kafka topic to ensure that none of the tweets were lost. Then Spark started it's work with two worker nodes to read data from the Kafka topic and to process the tweets, saving the result in a postgres table which fed a metabase dashboard.
Getting Tweets with Tweepy
Tweepy is a Python library that provides access to the entire Twitter REST API. After setting up a developer account in Twitter, the next step was to implement the code to get the tweets and send them to the previously created Kafka topic.
#read_twitter_data_stream.py
import tweepy
from kafka import KafkaProducer
from json import dumps
import os
import psycopg2
topic = os.environ.get("TOPIC_NAME")
api_key = os.environ.get("TWITTER_API_KEY")
api_secret = os.environ.get("TWITTER_API_SECRET")
bearer_token = os.environ.get("TWITTER_BEARER_TOKEN")
access_token = os.environ.get("TWITTER_ACCESS_TOKEN")
access_token_secret = os.environ.get("TWITTER_ACCESS_TOKEN_SECRET")
class TwitterStream(tweepy.StreamingClient):
# This function gets called when the stream is working
def on_connect(self):
print("Connected")
# This function gets called when a tweet passes the stream
def on_tweet(self, tweet):
# Displaying tweet in console
if tweet.referenced_tweets == None:
print(f"Sending to Kafka: {tweet.text}")
try:
producer.send(topic, tweet.text)
producer.flush()
except:
print("An exception occurred")
db_name = os.environ.get("POSTGRES_DB")
db_host = os.environ.get("POSTGRES_HOST")
db_user = os.environ.get("POSTGRES_USER")
db_pass = os.environ.get("POSTGRES_PASSWORD")
db_port = os.environ.get("POSTGRES_PORT")
conn = psycopg2.connect(database=db_name,
host=db_host,
user=db_user,
password=db_pass,
port=db_port)
cursor = conn.cursor()
cursor.execute('SET search_path TO streaming_data')
cursor.execute('SELECT value FROM streaming_data.term_search WHERE active is true')
results = cursor.fetchall()
conn.close()
if len(results) > 0:
for term in results:
print(f"Printing search term: {term[0]}")
producer = KafkaProducer(bootstrap_servers=['kafka:29092'],
value_serializer=lambda x:
dumps(x, ensure_ascii=False).encode('utf-8'))
client = tweepy.Client(bearer_token, api_key, api_secret,
access_token, access_token_secret)
auth = tweepy.OAuth1UserHandler(
api_key, api_secret, access_token, access_token_secret)
api = tweepy.API(auth)
# Creating Stream object
stream = TwitterStream(bearer_token=bearer_token)
print("Search for previous rules.")
previousRules = stream.get_rules().data
if previousRules:
print("Deleting previous rules.")
stream.delete_rules(previousRules)
for term in results:
stream.add_rules(tweepy.StreamRule(term[0]))
stream.filter(tweet_fields=["referenced_tweets"])
else:
print("No search term find in database. Aborting.")
The authentication details are being injected through an '.env' file.
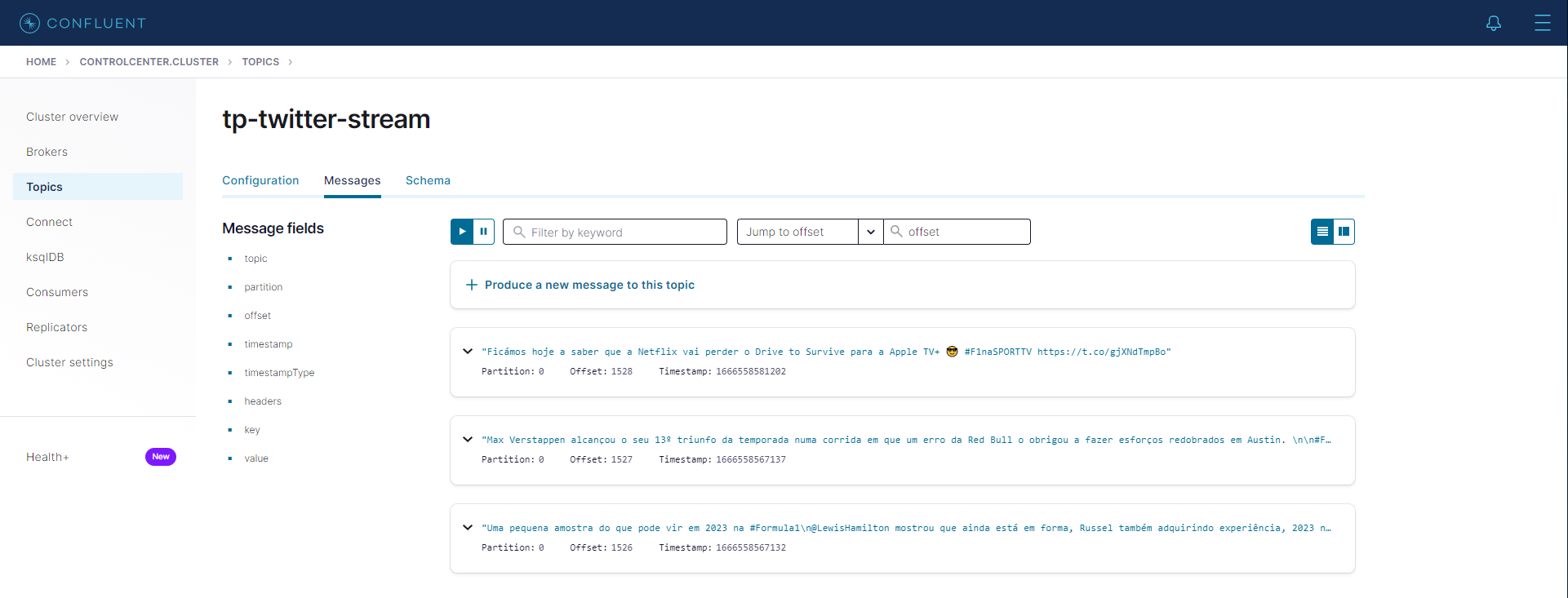
Queuing Data With Kafka
To set up Kafka I used a Docker image from Confluentinc. Confluentic also has a Docker image to manage the Kafka topics, so I installed the UI interface, which is named "control-center". To create the topic, the command I ran was:
kafka-topics --bootstrap-server kafka:29092 --create --if-not-exists --topic tp-twitter-stream --replication-factor 1 --partitions 1
Data (Real-time) Processing
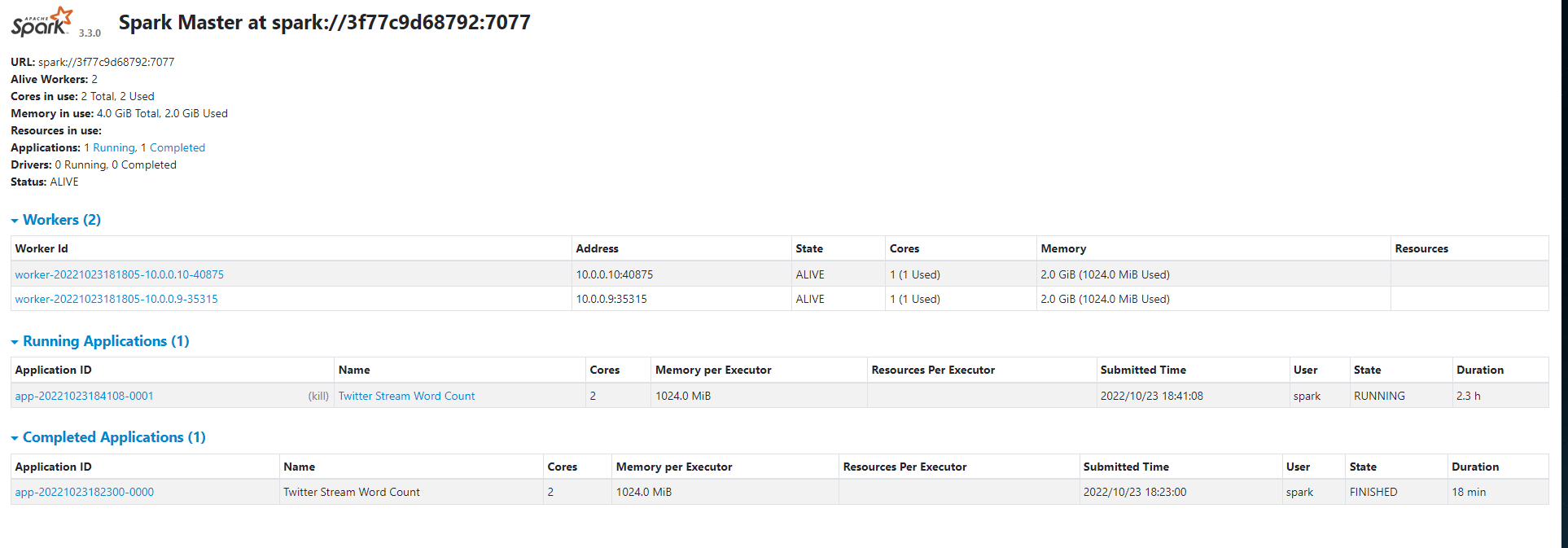
This was by far the most difficult part of all process. In my opinion, Spark is hard to learn. With no prior experience with Spark, I got very confused with how it works, then I realized that I should have start with Spark, instead of start with Spark Structured Streaming (which seems more complex). With PySpark, I was able to follow the docs available in Apache Spark website to get the implementation of word count done the correct way.
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
import os
db_name = os.environ.get("POSTGRES_DB")
db_host = os.environ.get("POSTGRES_HOST")
db_user = os.environ.get("POSTGRES_USER")
db_pass = os.environ.get("POSTGRES_PASSWORD")
db_port = os.environ.get("POSTGRES_PORT")
db_schema = os.environ.get("POSTGRES_SCHEMA")
db_target_properties = {"user": db_user, "password": db_pass, "driver": 'org.postgresql.Driver'}
db_connection_string = f"jdbc:postgresql://{db_host}:{db_port}/{db_name}?currentSchema={db_schema}"
def split_words(input_expression):
return explode(split(input_expression, " "))
def foreach_batch_function(df, id):
df.write.jdbc(url=db_connection_string,table='word_count', properties=db_target_properties, mode='overwrite')
pass
print("## Starting Processing ##")
spark = SparkSession \
.builder \
.appName("Twitter Stream Word Count") \
.master("spark://10.0.0.8:7077")\
.getOrCreate()
spark.sparkContext.setLogLevel("WARN")
print("## Creating session ##")
kafka_input_df = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "10.0.0.3:29092") \
.option("subscribe", "tp-twitter-stream") \
.option("startingOffsets", "earliest") \
.load()
print("## Listening to Kafka Topic ##")
# Split the lines into words
splited_words = split_words(kafka_input_df.value)
words_df = kafka_input_df.select(splited_words.alias("word"),kafka_input_df.timestamp.alias('time'))
# Take special chars out
words_df_clean = words_df.withColumn("word", regexp_replace(col("word"), "[^0-9a-zA-Z]+", ""))
counts_df = words_df_clean.withWatermark("time", "1 minutes").groupBy("word").count()
final_df = counts_df.writeStream.outputMode("complete").foreachBatch(foreach_batch_function).start()
final_df.awaitTermination()
Data Visualization
For data visualization, I used Metabase. It's an AMAZING product to build dashboards! Since I was short on time to finish this project, I decided to use Metabase again. I saw alternatives like Redash and Apache Superset but the complexity of their docker-compose files made my decision easy: there was no need to have a super complex product to show a simple desired chart.
Integrating all technologies with Docker
To integrate all of this technologies together, I've used Docker with docker-compose to simplify the management of the ten dockers.
Dockerfile:
FROM python:3
ENV PYTHONUNBUFFERED=1
RUN mkdir -p /app
WORKDIR /app
#Installing python dependencies
RUN pip install --upgrade pip
RUN pip install tweepy
RUN pip install kafka-python
RUN pip install psycopg2
COPY ./streaming-files/read_twitter_data_stream.py .
CMD ["/bin/bash", "-c", "/bin/sleep 60 && python ./read_twitter_data_stream.py"]
Docker Compose:
version: "2"
services:
zookeeper:
container_name: zookeeper
user: "0:0"
image: "confluentinc/cp-zookeeper:latest"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
restart: always
volumes:
- ./volume-data/zookeeper/data:/var/lib/zookeeper/data
- ./volume-data/zookeeper/log:/var/lib/zookeeper/log
networks:
containers-network:
ipv4_address: 10.0.0.2
kafka:
container_name: kafka
user: "0:0"
image: "confluentinc/cp-kafka:latest"
depends_on:
- zookeeper
ports:
- "9092:9092"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: "zookeeper:2181"
KAFKA_ADVERTISED_LISTENERS: "PLAINTEXT://kafka:29092,PLAINTEXT_HOST://localhost:9092"
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: "PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT"
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
restart: always
volumes:
- ./volume-data/kafka/data:/var/lib/kafka/data
networks:
containers-network:
ipv4_address: 10.0.0.3
control-center:
container_name: control-center
image: "confluentinc/cp-enterprise-control-center:latest"
hostname: control-center
depends_on:
- zookeeper
- kafka
ports:
- "9021:9021"
environment:
CONTROL_CENTER_BOOTSTRAP_SERVERS: "kafka:29092"
CONTROL_CENTER_ZOOKEEPER_CONNECT: "zookeeper:2181"
CONTROL_CENTER_REPLICATION_FACTOR: 1
CONTROL_CENTER_INTERNAL_TOPICS_PARTITIONS: 1
CONTROL_CENTER_MONITORING_INTERCEPTOR_TOPIC_PARTITIONS: 1
CONFLUENT_METRICS_TOPIC_REPLICATION: 1
PORT: 9021
restart: always
networks:
containers-network:
ipv4_address: 10.0.0.4
init-kafka:
container_name: init-kafka
image: confluentinc/cp-kafka:latest
depends_on:
- kafka
entrypoint: ["/bin/sh", "-c"]
command: |
"
# blocks until kafka is reachable
kafka-topics --bootstrap-server kafka:29092 --list
echo -e 'Creating kafka topics'
kafka-topics --bootstrap-server kafka:29092 --create --if-not-exists --topic tp-twitter-stream --replication-factor 1 --partitions 1
echo -e 'Successfully created the following topics:'
kafka-topics --bootstrap-server kafka:29092 --list
"
networks:
containers-network:
ipv4_address: 10.0.0.5
python-script:
container_name: python-script
build: ./
image: python:3
depends_on:
- zookeeper
- kafka
- init-kafka
- pg-streaming-db
environment:
- PYTHONUNBUFFERED=1
networks:
containers-network:
ipv4_address: 10.0.0.6
env_file:
- .env
pg-streaming-db:
container_name: pg-streaming-db
image: postgres:14.5-alpine
env_file:
- .env
volumes:
- ./volume-data/pg-streaming-db/data:/var/lib/postgresql/data
- ./sql-scripts/:/docker-entrypoint-initdb.d/
networks:
containers-network:
ipv4_address: 10.0.0.7
ports:
- 40000:5432
restart: always
spark:
container_name: spark
image: docker.io/bitnami/spark:3.3
environment:
- SPARK_MODE=master
- SPARK_RPC_AUTHENTICATION_ENABLED=no
- SPARK_RPC_ENCRYPTION_ENABLED=no
- SPARK_LOCAL_STORAGE_ENCRYPTION_ENABLED=no
- SPARK_SSL_ENABLED=no
ports:
- "8080:8080"
networks:
containers-network:
ipv4_address: 10.0.0.8
depends_on:
- kafka
- python-script
env_file:
- .env
restart: always
spark-worker-1:
container_name: spark-worker-1
image: docker.io/bitnami/spark:3.3
environment:
- SPARK_MODE=worker
- SPARK_MASTER_URL=spark://spark:7077
- SPARK_WORKER_MEMORY=2G
- SPARK_WORKER_CORES=1
- SPARK_RPC_AUTHENTICATION_ENABLED=no
- SPARK_RPC_ENCRYPTION_ENABLED=no
- SPARK_LOCAL_STORAGE_ENCRYPTION_ENABLED=no
- SPARK_SSL_ENABLED=no
networks:
containers-network:
ipv4_address: 10.0.0.9
depends_on:
- spark
#command: "spark-submit --master spark://spark:7077 --packages org.apache.spark:spark-sql-kafka-0-10_2.12:3.3.0 /opt/bitnami/spark/spark-scripts/spark_stream_process.py"
volumes:
- ./spark-scripts/:/opt/bitnami/spark/spark-scripts
restart: always
spark-worker-2:
container_name: spark-worker-2
image: docker.io/bitnami/spark:3.3
environment:
- SPARK_MODE=worker
- SPARK_MASTER_URL=spark://spark:7077
- SPARK_WORKER_MEMORY=2G
- SPARK_WORKER_CORES=1
- SPARK_RPC_AUTHENTICATION_ENABLED=no
- SPARK_RPC_ENCRYPTION_ENABLED=no
- SPARK_LOCAL_STORAGE_ENCRYPTION_ENABLED=no
- SPARK_SSL_ENABLED=no
networks:
containers-network:
ipv4_address: 10.0.0.10
depends_on:
- spark
restart: always
metabase-app:
container_name: metabase-app
image: metabase/metabase
ports:
- 3000:3000
environment:
MB_DB_TYPE: postgres
MB_DB_DBNAME: metabase
MB_DB_PORT: ${POSTGRES_PORT}
MB_DB_USER: ${POSTGRES_USER}
MB_DB_PASS: ${POSTGRES_PASSWORD}
MB_DB_HOST: ${POSTGRES_HOST}
depends_on:
- pg-streaming-db
links:
- pg-streaming-db
env_file:
- .env
networks:
containers-network:
ipv4_address: 10.0.0.11
restart: always
networks:
containers-network:
driver: bridge
ipam:
config:
- subnet: 10.0.0.0/16
gateway: 10.0.0.1
Some considerations:
- Zookeeper, Kafka and Control Center are provided by Confluentinc
- init-kafka container was usefull to create the kafka topic if it not exists
- python-script was the docker that runs the tweepy script to get the tweets and insert them into database
- There was a need to create a docker network to solve the connection to the DB docker. The solution was to use a static IP address so the host never changes
- There was a problem with spark, spark-worker-1 and spark-worker-2. When setting the command to the master run, it was thrown an error because the spark workers were not running at the time. When I tried to set the PySpark script to run on the worker, the job registered to work, but the worker died right after. Since I could not solve this issue (probably due to some config error), I started the PySpark script manually
- The python-script waits 60 seconds before all of the containers are up, to call the twitter API.
The commands needed to up the dockers were:
docker compose build --no-cache
docker compose up -d
docker cp ./spark-scripts/spark_stream_process.py spark:/opt/bitnami/spark/spark_stream_process.py
docker exec spark /opt/bitnami/spark/bin/spark-submit --packages org.postgresql:postgresql:42.5.0,org.apache.spark:spark-sql-kafka-0-10_2.12:3.3.0 /opt/bitnami/spark/spark_stream_process.py

Testing & Cleaning
Because I'm a huge fan of Formula 1, I decided to put this to work on a F1 Grand Prix day with the race in Austin, Texas. To achieve that, I registered in database the word "#F1naSPORTTV" and waited for the results to see what word was the most written in Twitter. There was immediately a problem! The machine running the containers was a GCP e2-standard-2 (2 vCPU and 8 GB of memory). The CPUs were at their maximium capacity with processing being slow. So, just to test the speed of processing, I changed to a e2-standard-4 (4 vCPU and 16 GB of memory). The all process was a lot more smooth afer the change of resources available.
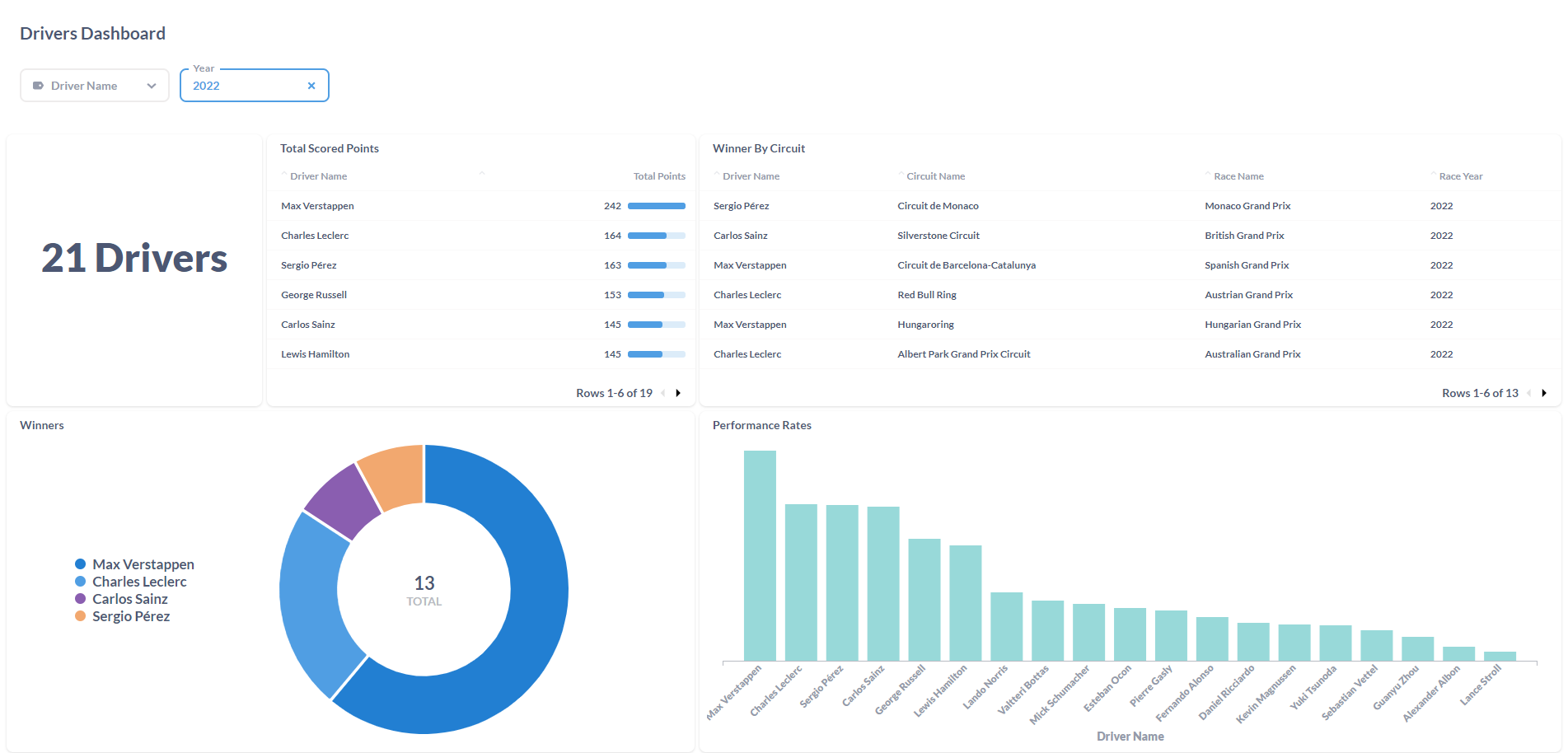
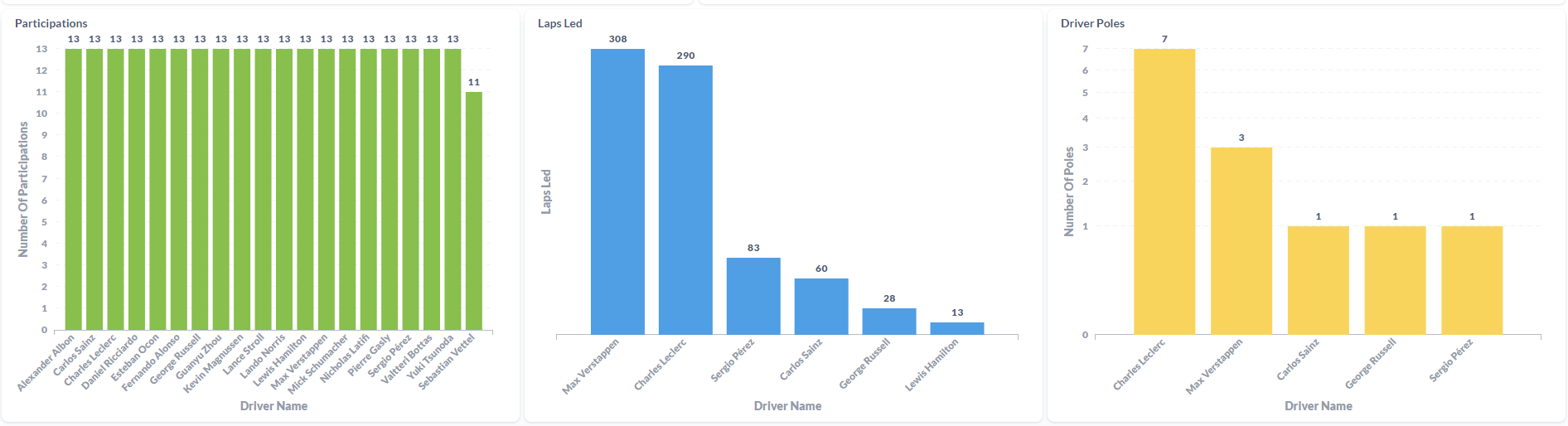
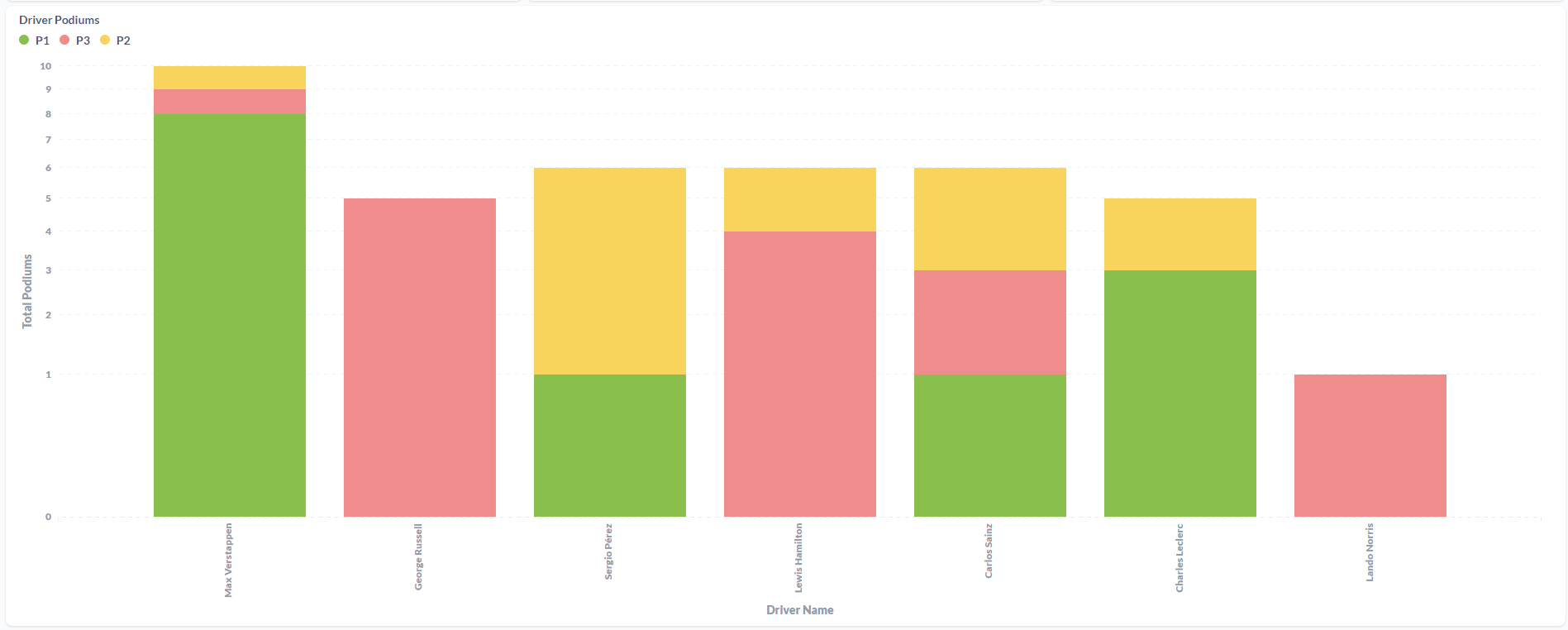
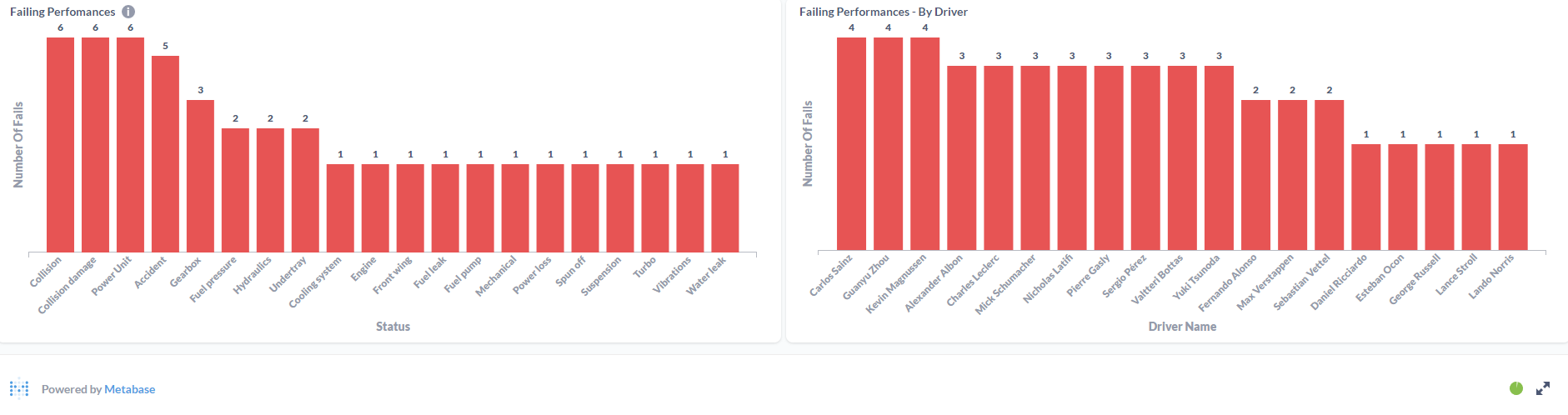
After cleaning data the AustinGP Word count the results were:
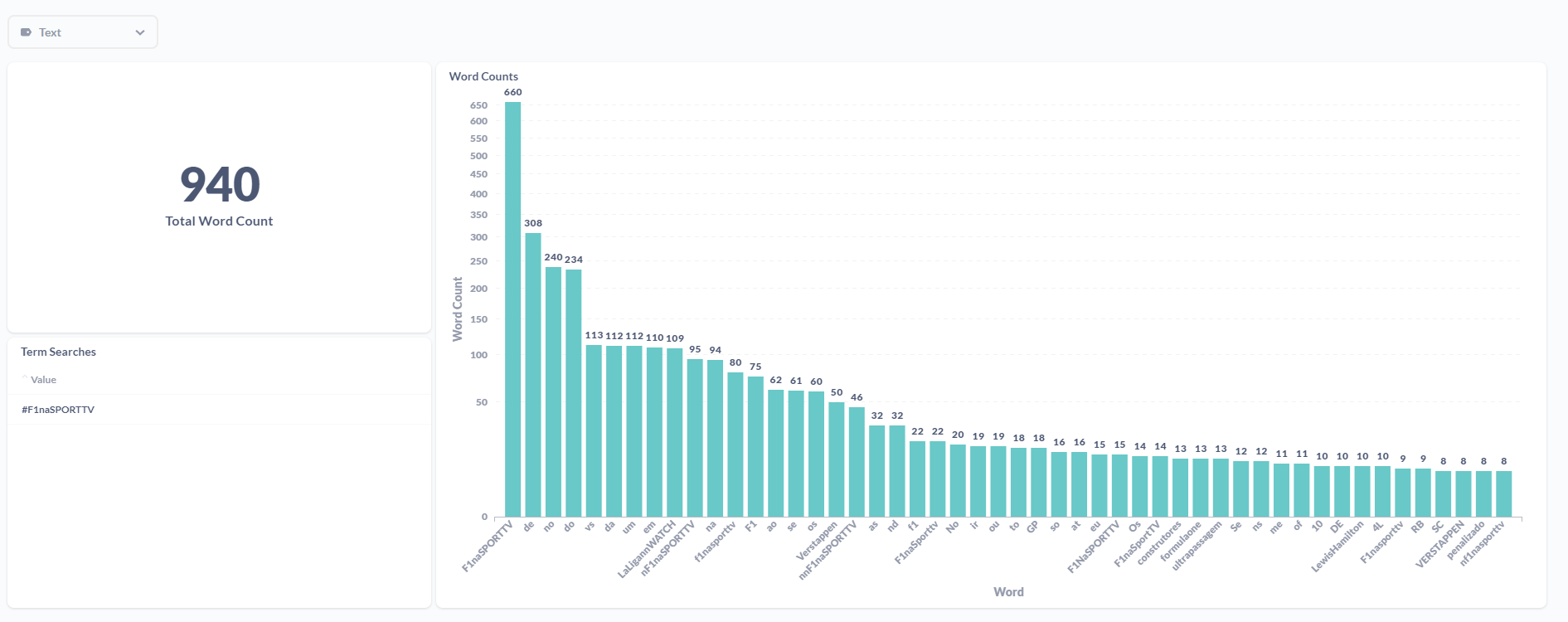
To be honest, I was not expecting that much "dirty" data. I think when I understand the full capacity of Spark i'll be able to filter the data before processing it. Since this is just a little PoC, I did the process of cleaning the dirty data manually:
delete from word_count wc where length(word) > 20 or length(word) < 2;
With this, I took out the big words and the small ones also, that does not make sense.
Conclusions & Further Steps
Understanding Spark was the most difficult part of this project, but in the end I think I gave one more step to understand it's concepts. I plan to keep working with Spark in order to be better with it and to do more complex stuff.
Future steps:
- Improve overall logging
- Configure Kafka with some details (for example, retention time)
- Solve a problem with the start of PySpark job mentioned early
- Create an UI to register in DB the wanted term to search instead of beeing manually added
- In Spark, change the Dataframe to filter the words with little characters
- Implement some sentiment analysis with the words read from twitter
Due to the costs of having the VM running under a GCP VM Instance, the current pipeline is only available if I start the VM manually.