Web Scraping - Portuguese Parliament Voting
Scraping data from portuguese parliament with the help of Python library called Beautiful Soap.
Overview
The main goal of this project was to learn how to do data extaction with web scraping. In order to practice web scraping I choosed the Portuguese Parliament Voting website to get all of the votings since 2012. The goal was to extract, process and provide an interactive dashboard to see the votings, allowing the possibility to filter by party and year.
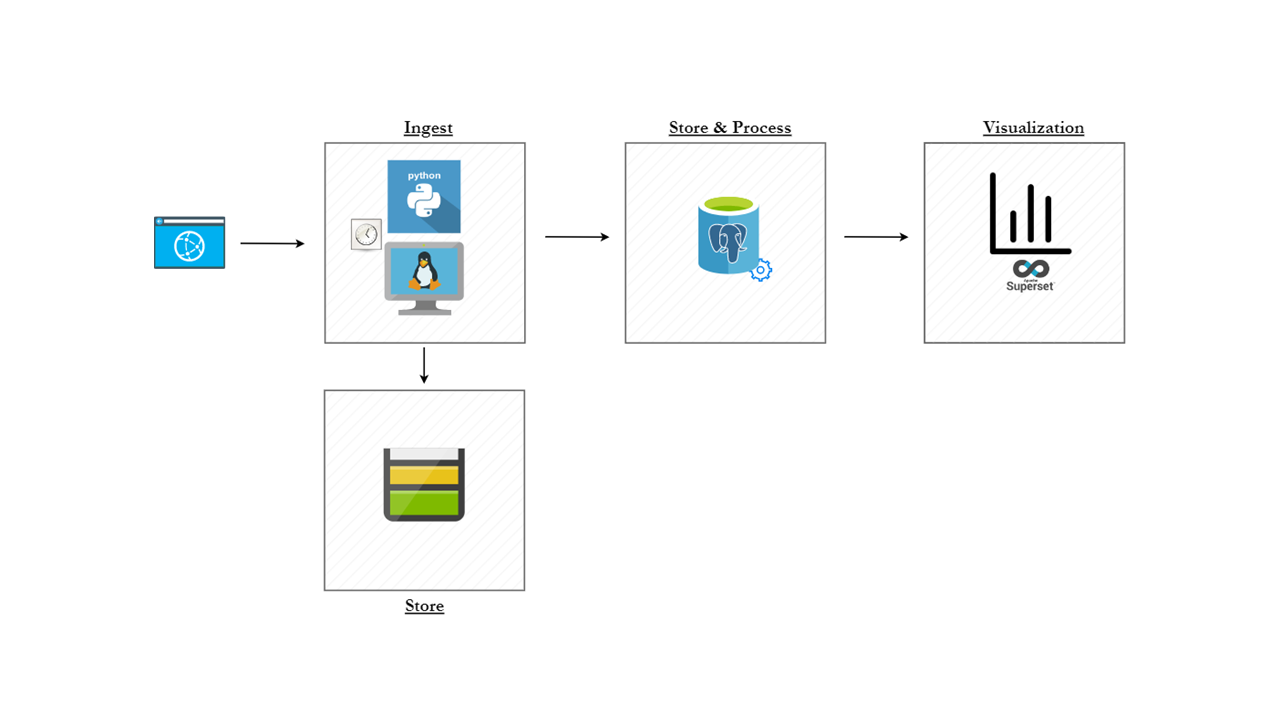
To allow this, my implementation was based on the following architectural diagram:
The components used were:
- Azure Cloud
- Azure Storage Account
- Azure Postgres Database (with Flexible Servers)
- docker
- Apache Superset
Data Ingestion
To ingest the data from the voting website I used Python with a library called Beautiful Soap. With this, I was able to iterate for each voting entry and save the available PDF file and upload it to an Azure Storage Account. That was achieved with the following code:
def scrap_voting_website(self, url, text_to_search, container_name):
page = requests.get(url)
soup = BeautifulSoup(page.content, "html.parser")
results = soup.find(
id="ctl00_ctl50_g_ef1010ac_1ad2_43f3_b329_d1623b7a1246_ctl00_pnlUpdate")
job_elements = results.find_all(
"div", class_="row home_calendar hc-detail")
for job_element in job_elements:
date = job_element.find("p", class_="date")
year = job_element.find("p", class_="time")
date_fmt = date.text.strip()
year_fmt = year.text.strip()
links = job_element.find_all("a", href=True)
# Iterates for all pdfs and downloads the links to access the site
for link in links:
for text in text_to_search:
if text.casefold() in link.text.strip().casefold():
url = link['href']
file_utils = FileUtils()
file_utils.download_file_upload_az_storage(
url, link.text.strip(), date_fmt, year_fmt, container_name)
To perform the upload to the azure data storage:
def download_file_upload_az_storage(self, *args):
try:
filename = f"{args[1]}_{args[2]}.{args[3]}.pdf"
filename = filename.replace('/', '_').replace(' ', '_').replace('\\', '_').replace('-', '_')
file = Path(f"polls-pdfs/{args[3]}/{filename}")
print(f"Downloading {filename}.", flush=True)
response = requests.get(args[0])
file.write_bytes(response.content)
except requests.exceptions.HTTPError as errh:
print ("Http Error:",errh, flush=True)
except requests.exceptions.ConnectionError as errc:
print ("Error Connecting:",errc, flush=True)
except requests.exceptions.Timeout as errt:
print ("Timeout Error:",errt, flush=True)
except requests.exceptions.RequestException as err:
print ("RequestException: General Error",err, flush=True)
azure_utils = AzureUtils()
container_name = args[4] + "/"+ args[3]
print(f"Uploading {filename} to container {container_name}.")
azure_utils.upload_blob_to_container(container_name, file, filename)
As a result, the PDF files downloaded from voting site was uploaded to the existing Azure Storage Account. The download_file_upload_az_storage function downloads the file and uploads it to the container inside the storage account. Each downloaded file is divided by year.
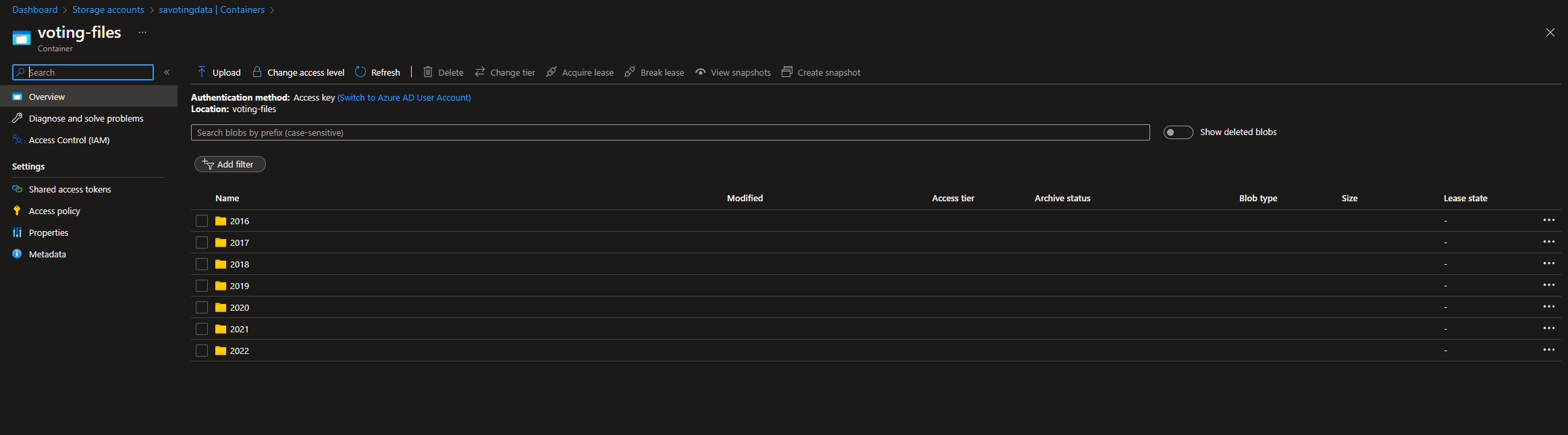
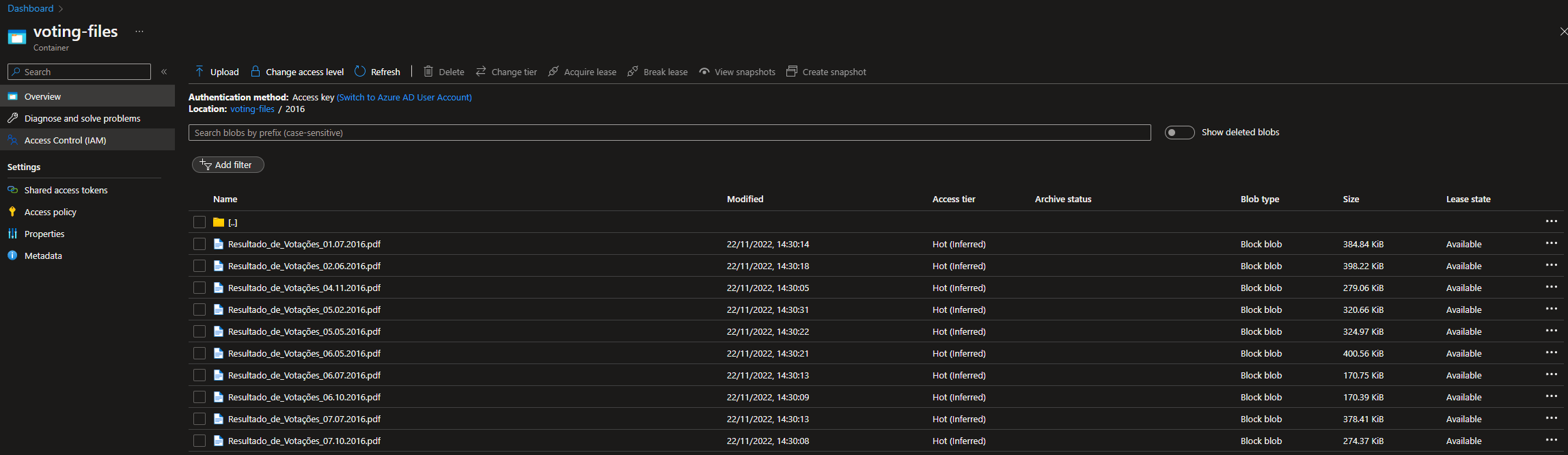
After upload the PDF files to the Storage Account, I've used a library called PyPDF2 to read all PDF files and take out all of the URLs. This was achieved with the following function:
def get_url_from_pdf_files(self, destination_folder, url_to_filter, arr_url_initiatives):
for filename in os.listdir(destination_folder):
PDFFile = open(f"{destination_folder}/{filename}", 'rb')
PDF = PyPDF2.PdfFileReader(PDFFile)
pages = PDF.getNumPages()
key = '/Annots'
uri = '/URI'
ank = '/A'
for page in range(pages):
pageSliced = PDF.getPage(page)
pageObject = pageSliced.getObject()
if key in pageObject.keys():
ann = pageObject[key]
for a in ann:
u = a.getObject()
if uri in u[ank].keys() and url_to_filter.casefold() in u[ank][uri].casefold():
if not u[ank][uri] in arr_url_initiatives:
arr_url_initiatives.append(u[ank][uri])
return arr_url_initiatives
With the array filled with the existing URLs from voting details page, it was time to scrape the voting details page.
I = 1
for url in arr_url_initiatives:
print(f"{str(I)} || Scraping initiative urls to get voting details.", flush=True)
arr_voting_data = scrapper_utils.scrap_initiative_website(url, arr_voting_data)
I += 1
Having the arr_voting_data filled with all of the voting model object details, it was time to insert this data into a Postgres Database. To achieve that, I've made a class that connects to the Postgres Server running on Azure and inserts the data in the staging_data schema created.
import psycopg2
import os
from dotenv import load_dotenv
load_dotenv() # take environment variables from .env.
db_name = os.environ.get("POSTGRES_DB")
db_host = os.environ.get("POSTGRES_HOST")
db_user = os.environ.get("POSTGRES_USER")
db_pass = os.environ.get("POSTGRES_PASSWORD")
db_port = os.environ.get("POSTGRES_PORT")
db_schema = os.environ.get("POSTGRES_SCHEMA")
class AZdbUtils:
def connect(self):
try:
conn = psycopg2.connect(database=db_name,
host=db_host,
user=db_user,
password=db_pass,
port=db_port)
except (Exception, psycopg2.DatabaseError) as error:
print(error)
return conn
def upload_data_db(self, arr_voting_data):
conn = self.connect()
cursor = conn.cursor()
for data in arr_voting_data:
print('Inserting data for initiative: ' + data.get_title(), flush=True)
cursor.execute('INSERT INTO staging_data.scraped_data (title, text, status, url, date, voting_favor, voting_against, voting_abstention, voting_absent) VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s)',
(data.get_title(), data.get_text(), data.get_status(), data.get_url(), data.get_date(), data.get_voting_favor(), data.get_voting_against(), data.get_voting_abstention(), data.get_voting_absent()))
conn.commit()
print('Executing transform function', flush=True)
cursor.execute('select staging_data.func_transform_staging_data();')
conn.commit()
if conn is not None:
conn.close()
print('Database connection closed.', flush=True)
Data Processing
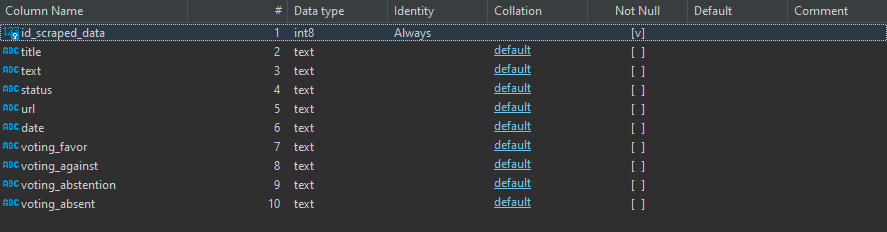
As you can see in the previous chapter, the final step of the upload_data_db function is to call a function named func_transform_staging_data. This function cleans the data and processes it to insert in the refined_data schema.
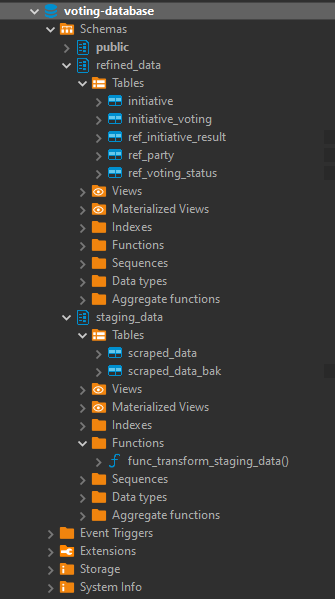
The two created schemas are:
- staging_data - scraped data is inserted in "raw" format.
- Table scraped_data
- Table scraped_data
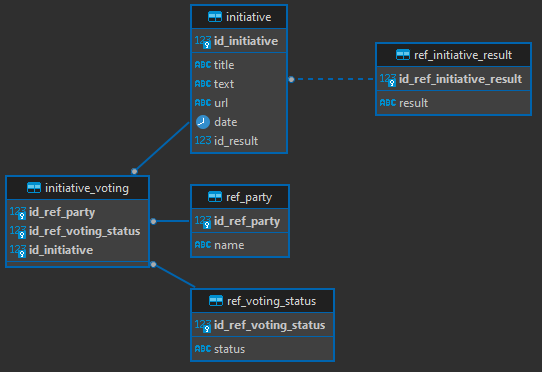
- refined_data - post-processed data
- Table initiative - Stores the initiative details (text, title, created date, url)
- Table initiative_voting - Stores the foreign keys to party, voting_status and initiative tables. The combination of the three keys make one composed primary key.
- Table ref_party - Stores the party details
- Table ref_initiative_result - Stores the initiative result details (approved, not approved, approved by all)
- Table ref_voting_status - Stores the initiative voting (favor, against, absent, away)
To perform the data transformation, I've created the following Postgres function:
CREATE OR REPLACE FUNCTION staging_data.func_transform_staging_data()
RETURNS integer
LANGUAGE plpgsql
AS $function$
declare
SUCCESS INTEGER;
_row record;
r_voting_favor text;
r_voting_against text;
r_voting_abstention text;
r_voting_away text;
error_loop bool;
ret_initiative_id BIGINT;
party_vote_iterator integer;
arr_voting_favor bigint[] DEFAULT ARRAY[]::bigint[];
arr_voting_against bigint[] DEFAULT ARRAY[]::bigint[];
arr_voting_abstent bigint[] DEFAULT ARRAY[]::bigint[];
arr_voting_away bigint[] DEFAULT ARRAY[]::bigint[];
aux_id_ref_party bigint;
id_status_favor int;
id_status_against int;
id_status_abstent int;
id_status_away int;
id_initiative_result int;
begin
SUCCESS = 1;
truncate table refined_data.initiative cascade;
truncate table refined_data.initiative_voting cascade;
select id_ref_voting_status into id_status_favor from refined_data.ref_voting_status rvs where lower(status) = lower('Favor');
select id_ref_voting_status into id_status_against from refined_data.ref_voting_status rvs where lower(status) = lower('Contra');
select id_ref_voting_status into id_status_abstent from refined_data.ref_voting_status rvs where lower(status) = lower('Abstenção');
select id_ref_voting_status into id_status_away from refined_data.ref_voting_status rvs where lower(status) = lower('Ausente');
for _row in select REGEXP_REPLACE(voting_favor, '{*}*"*', '', 'gm') AS voting_favor,
REGEXP_REPLACE(voting_against, '{*}*"*', '', 'gm') AS voting_against,
REGEXP_REPLACE(voting_abstention, '{*}*"*', '', 'gm') AS voting_abstention,
REGEXP_REPLACE(voting_absent, '{*}*"*', '', 'gm') AS voting_absent,
id_scraped_data , title , "text", status , url, "date"
from
staging_data.scraped_data sd
where
trim(status) <> '' and (voting_favor <> '{}' or voting_against <> '{}' or voting_abstention <> '{}' or voting_absent <> '{}')
and trim(date) <> ''
order by id_scraped_data asc
loop
ret_initiative_id = -1;
arr_voting_favor := '{}';
arr_voting_against := '{}';
arr_voting_abstent := '{}';
arr_voting_away := '{}';
select id_ref_initiative_result into id_initiative_result from refined_data.ref_initiative_result rvs where lower(result) = lower(_row.status);
raise notice 'Iterate favor parties';
for r_voting_favor in select unnest(string_to_array(_row.voting_favor,','))
loop
if r_voting_favor ~ '^[A-Z-]*$' then
raise notice 'Favor party % match', r_voting_favor;
select id_ref_party into aux_id_ref_party from refined_data.ref_party rp where lower(name) like lower(r_voting_favor);
arr_voting_favor := arr_voting_favor || aux_id_ref_party;
end if;
end loop;
raise notice 'Iterate against parties';
for r_voting_against in select unnest(string_to_array(_row.voting_against,','))
loop
if r_voting_against ~ '^[A-Z-]*$' then
raise notice 'Against party % match', r_voting_against;
select id_ref_party into aux_id_ref_party from refined_data.ref_party rp where lower(name) like lower(r_voting_against);
arr_voting_against := arr_voting_against || aux_id_ref_party;
end if;
end loop;
raise notice 'Iterate abstentions parties';
for r_voting_abstention in select unnest(string_to_array(_row.voting_abstention,','))
loop
if r_voting_abstention ~ '^[A-Z-]*$' then
raise notice 'Absentee party % match ', r_voting_abstention;
select id_ref_party into aux_id_ref_party from refined_data.ref_party rp where lower(name) like lower(r_voting_abstention);
arr_voting_abstent := arr_voting_abstent || aux_id_ref_party;
end if;
end loop;
raise notice 'Iterar absent parties';
for r_voting_away in select unnest(string_to_array(_row.voting_absent,','))
loop
if r_voting_away ~ '^[A-Z-]*$' then
raise notice 'Absent party % match', r_voting_away;
select id_ref_party into aux_id_ref_party from refined_data.ref_party rp where lower(name) like lower(r_voting_away);
arr_voting_away := arr_voting_away || aux_id_ref_party;
end if;
end loop;
raise notice 'Inserting initiative: %.', _row.title;
insert into refined_data.initiative (title, "text", url, "date", id_result)
values (_row.title, _row.text, _row.url, _row.date::date, id_initiative_result::integer)
RETURNING id_initiative INTO ret_initiative_id;
raise notice 'Inserting favor votes to iniative.';
FOREACH party_vote_iterator IN ARRAY arr_voting_favor
LOOP
insert into refined_data.initiative_voting (id_ref_party, id_ref_voting_status, id_initiative) values (party_vote_iterator, id_status_favor, ret_initiative_id);
END LOOP;
raise notice 'Inserting against votes to iniative.';
FOREACH party_vote_iterator IN ARRAY arr_voting_against
LOOP
insert into refined_data.initiative_voting (id_ref_party, id_ref_voting_status, id_initiative) values (party_vote_iterator, id_status_against, ret_initiative_id);
END LOOP;
raise notice 'Inserting abstent votes to iniative.';
FOREACH party_vote_iterator IN ARRAY arr_voting_abstent
LOOP
insert into refined_data.initiative_voting (id_ref_party, id_ref_voting_status, id_initiative) values (party_vote_iterator, id_status_abstent, ret_initiative_id);
END LOOP;
raise notice 'Inserting away votes to iniative.';
FOREACH party_vote_iterator IN ARRAY arr_voting_away
LOOP
insert into refined_data.initiative_voting (id_ref_party, id_ref_voting_status, id_initiative) values (party_vote_iterator, id_status_away, ret_initiative_id);
END LOOP;
end loop;
truncate table staging_data.scraped_data;
return SUCCESS;
end;
$function$
;
This function selects each record from the staging_schema, checks if the party exists - with the use of a regex expression - and then inserts the data into the refined_schema tables. There was a need to implement this because there are votes that are not done by parties, but by single deputies and those, I did not considered to this project.
Data Visualization
Since I'm a huge fan of Metabase, as I did use in other projects, I've decided to switch to Apache Superset to learn how it works. Now I'm a huge fan of Apache Superset as I am of Metabase! To install Superset I've just followed the install guide present in their website. Superset allows to do querys that are refered as datasets. Having the result of the queries, we can create the dashboards, based on them.
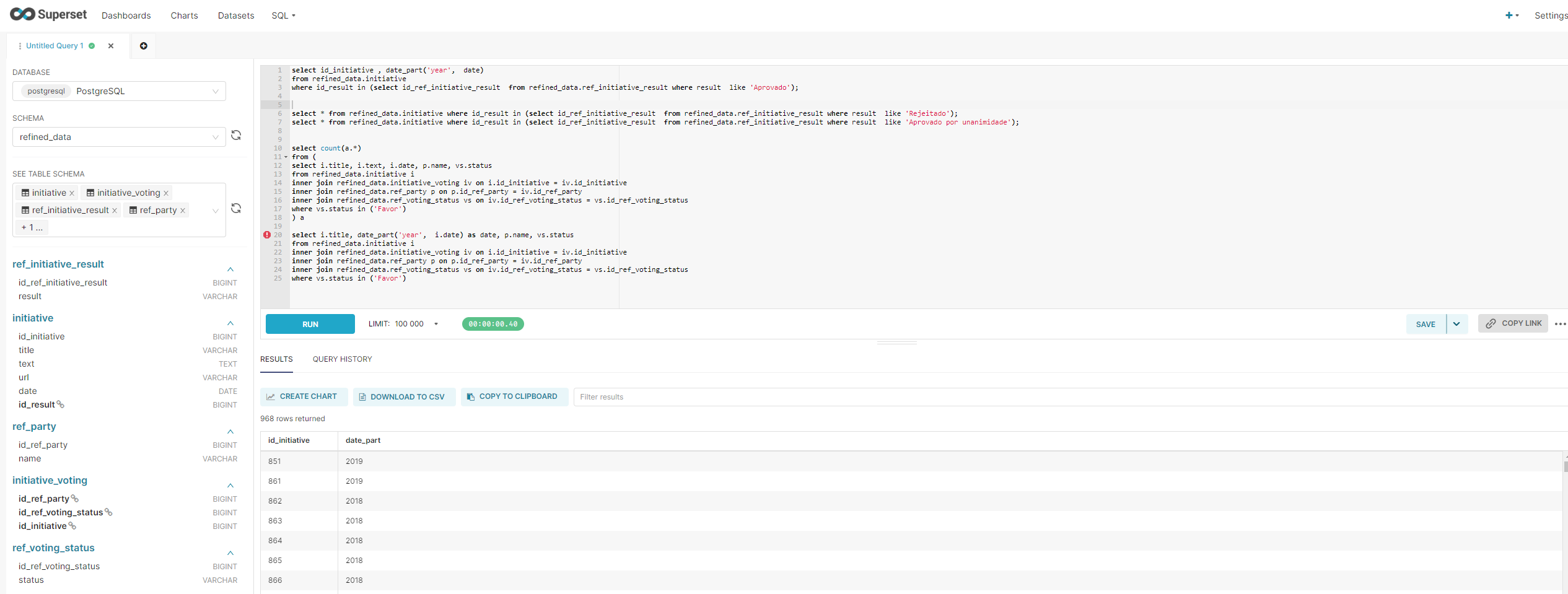
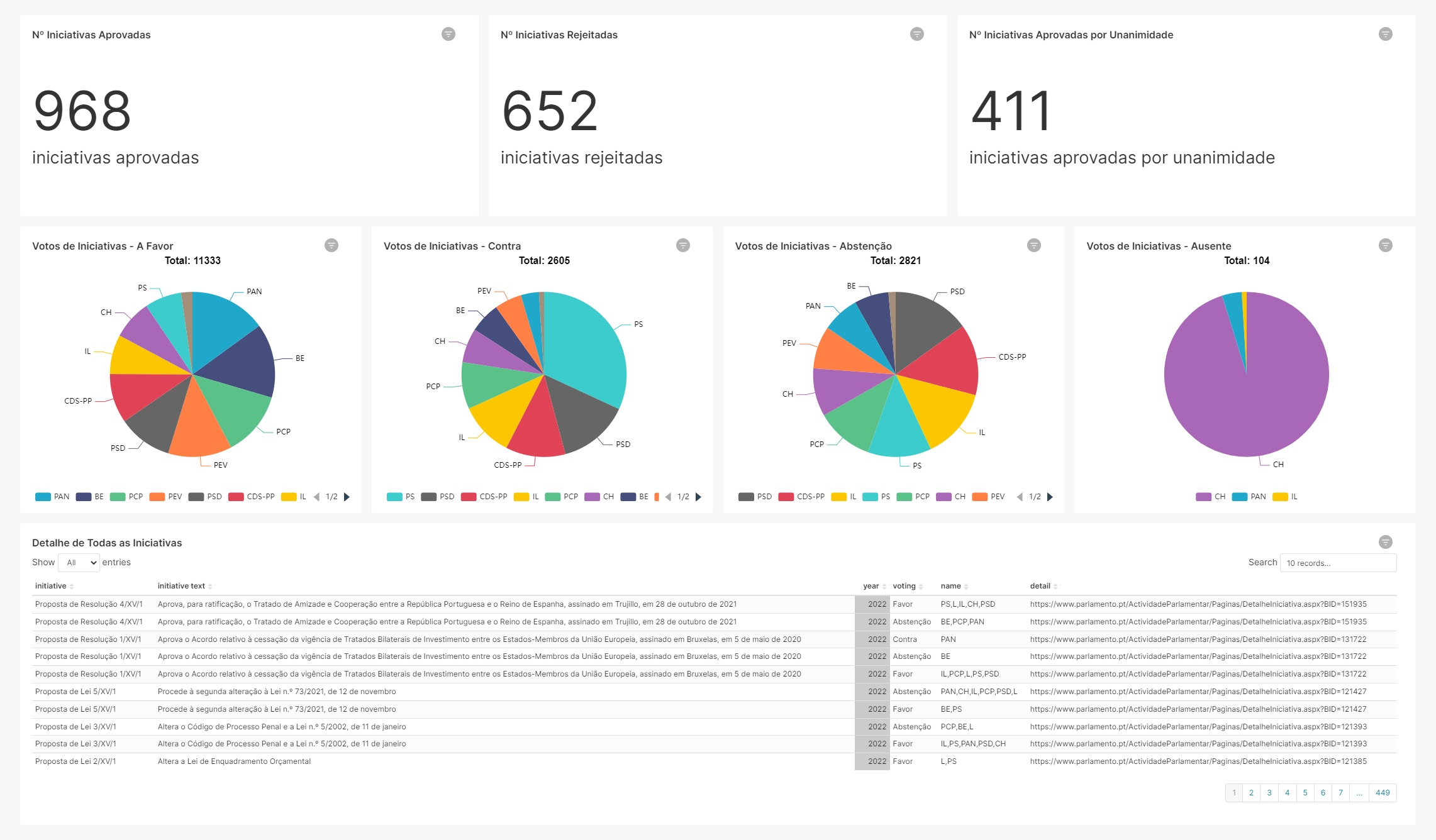
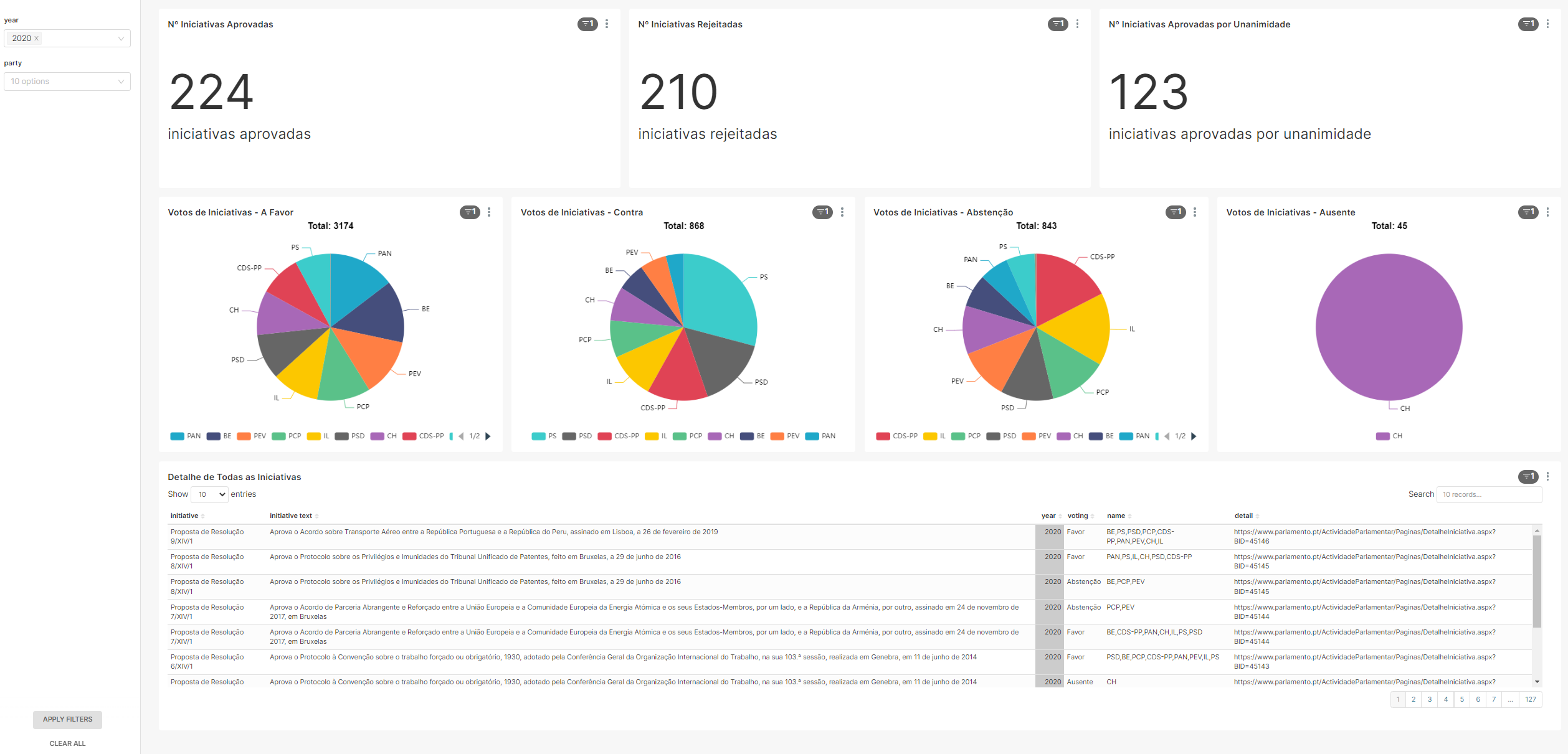
After creating all queries, the final dashboard displays the following information:
- Number of approved initiatives
- Number of rejected initiatives
- Number of approved by all initiatives
- Favor votes
- Against votes
- Abtsent votes
- Away party when voting occured
- Detail of all initiatives
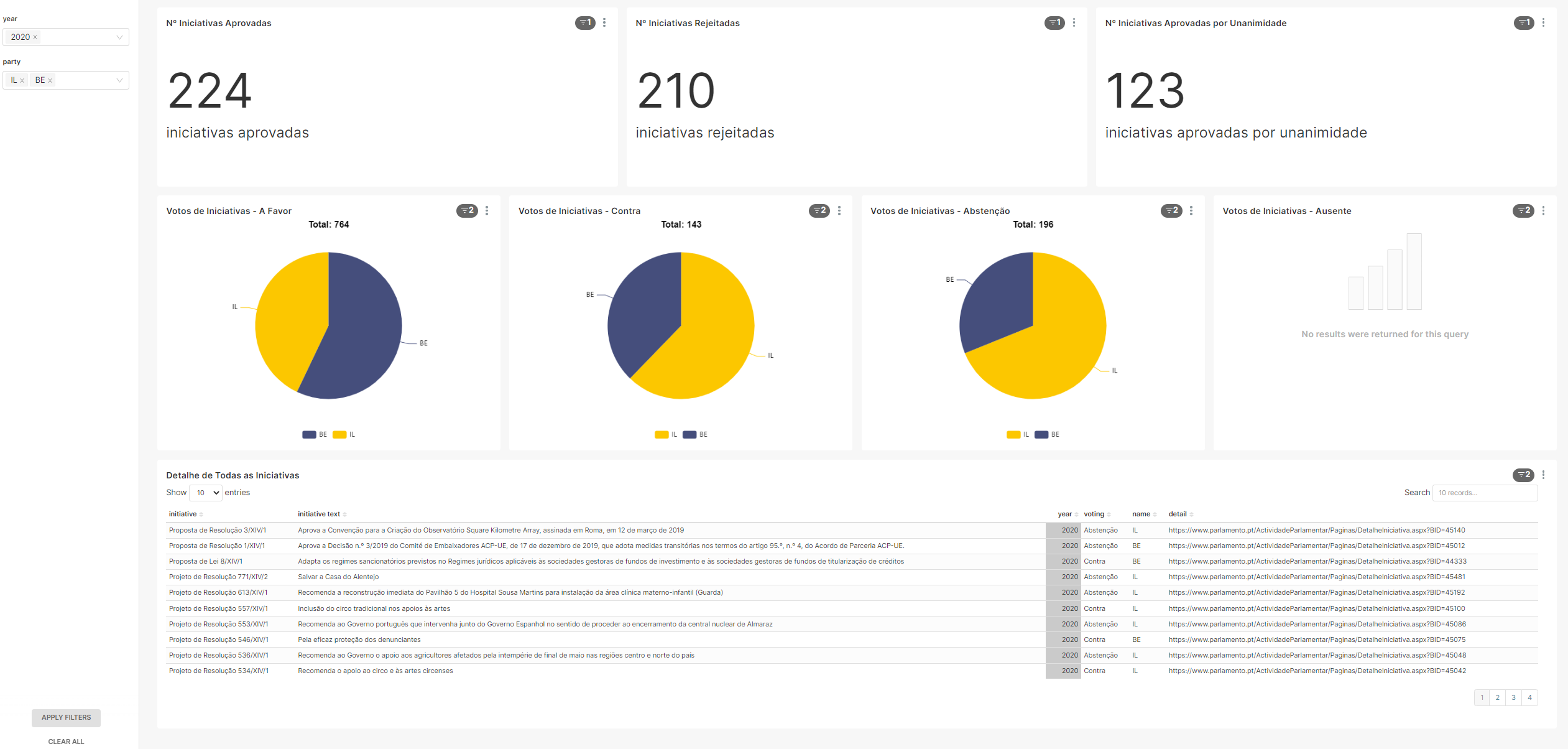
With the possibility to add filters by year and party:
Integrating all technologies
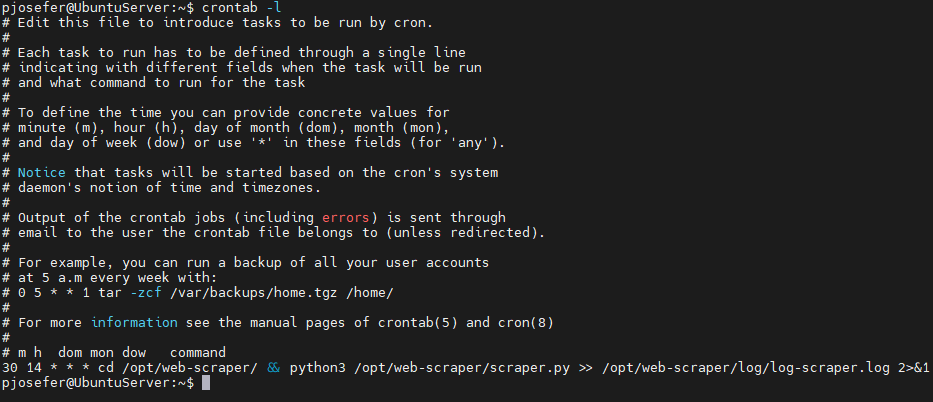
Integrating this technologies was achieved by creating a cron job on the Azure VM instance - running with Ubuntu Server - to, at 2:30 pm each day runs the scraper.py script that scrapes the voting website, downloads the pdf files, uploads it to Azure Storage and inserts into the staging dataset.
When running, the script displays the following output, when downloading the PDF files:
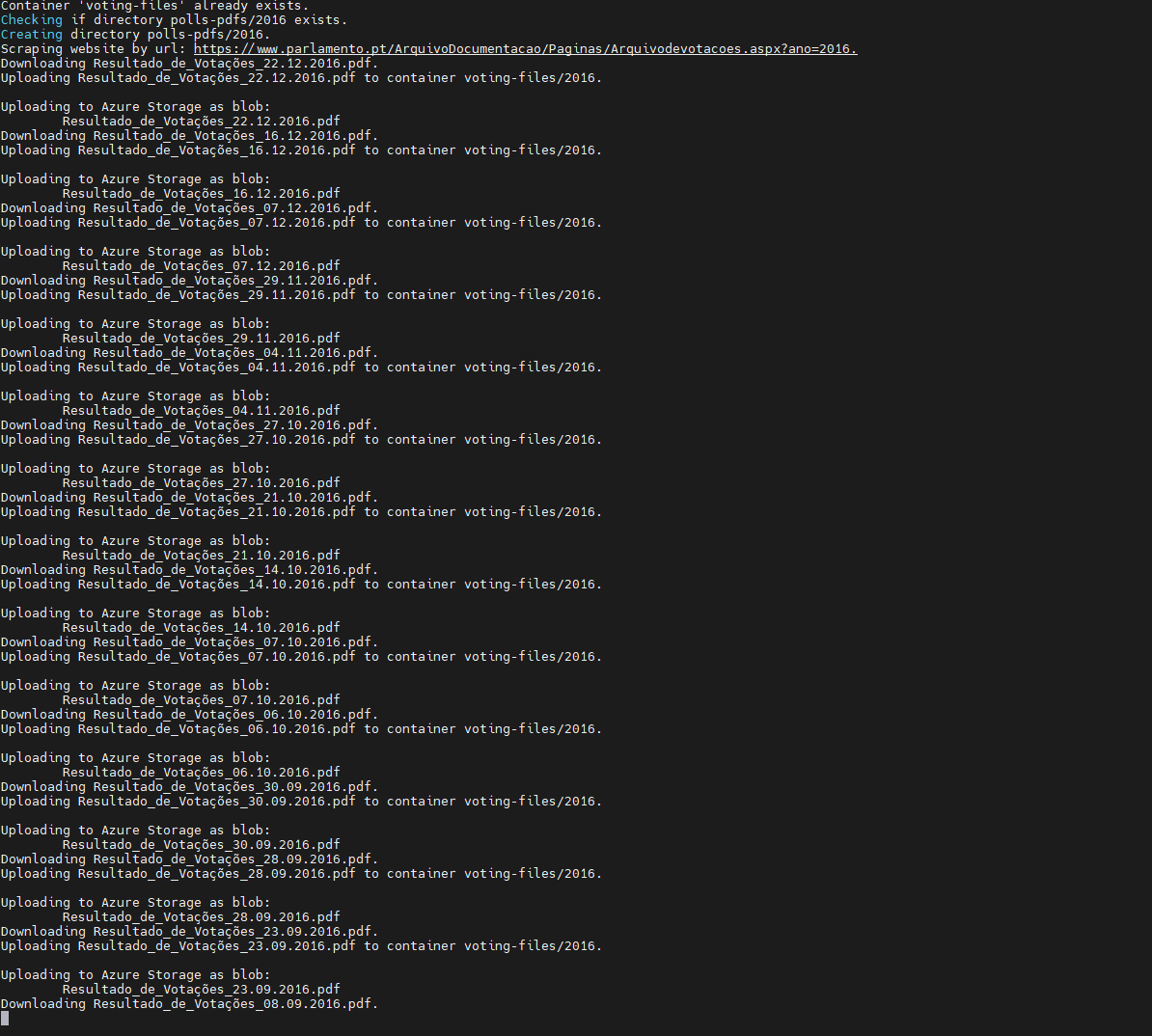
Scraping the voting details website:
To achieve this pipeline, I've created an Azure Free Account to allow me to better know how Microsoft cloud works.
Conclusions & Further Steps
I'm quite happy with this project. It helped me to know Azure products in practice, after I done the Azure Fundamentals Certification. I've had some difficulties with the scraping API because the voting website does not follow the same structure across the different voting pages. Besides that, since this was a limited time subscription (to avoid costs on my side), I think I've achieved a great final result. In the future, I plan to include the individual deputy votes and count them in the final votation.