F1 Data Pipeline
ELT Pipeline to Extract, Load and Transform F1 Data using Kaggle API, Docker, Python, GCP Cloud Storage, GCP BigQuery and Metabase
Overview
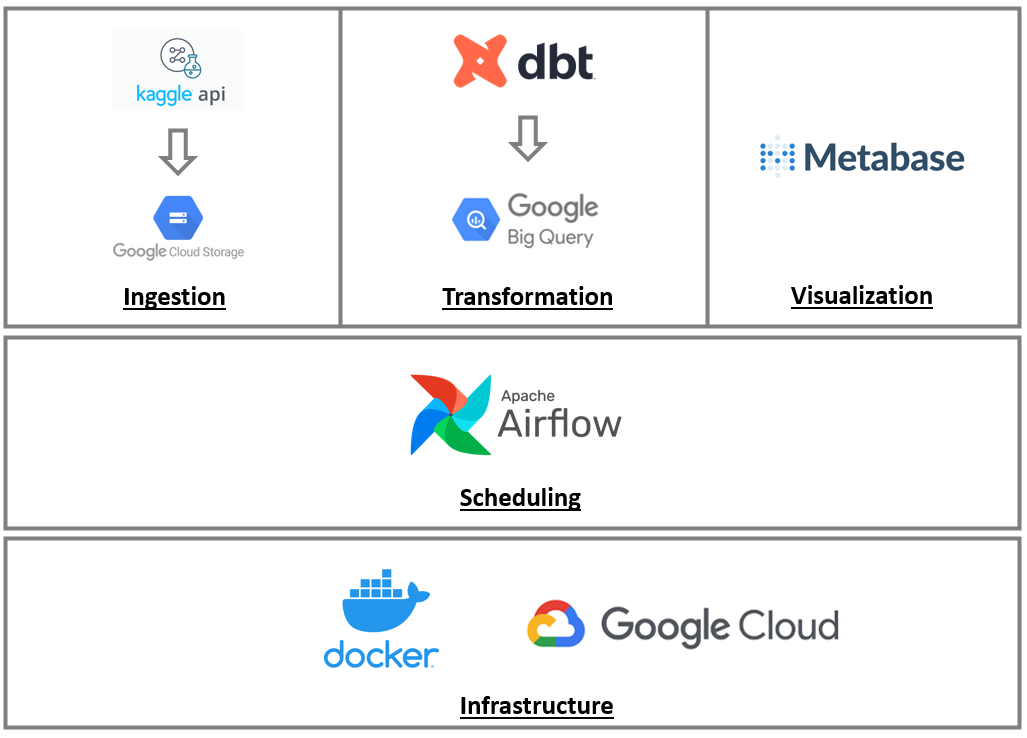
As a software engineer, this is the first ever data pipeline i built. The goal was to gain experience with modern technologies in data universe. This pipeline is scheduled to run daily( as there is no fixed data for F1 data updates). The scheduling is done by airflow and it has two DAGs. The first one is responsible for getting data from Kaggle API (in CSV files format), transforming it to parquet files, loading into Google Cloud Storage and creating a staging dataset. After this step is complete, an airflow sensor in the second DAG is triggered and it will call the dbt tool to perform the transformations needed and load them into Google BigQuery as a "refined dataset". Once completed, data will be available in dashboards created with the help of Metabase dashboards.
This data pipeline could not be done wihtout help from Data Talks Club Team and their Data Engineering Course.
Data Extraction
The first step was to get F1 Data from Kaggle through Kaggle API and Python. After the zip file was downloaded, it was removed from filesystem in order to clear the workspace.
def download_data(directory):
logging.info(f"Starting ingestion - Searching for files in directory: {directory}")
try:
logging.info("Instancianting KaggleAPI.")
api = KaggleApi()
logging.info("Authenticating KaggleAPI.")
api.authenticate()
logging.info("Downloading files ... ")
api.dataset_download_files('rohanrao/formula-1-world-championship-1950-2020', path=f"{directory}")
list_dir = os.listdir(f"{directory}")
total_downloaded_files = len(list_dir)
logging.info(f"Downloaded {total_downloaded_files} files.")
if(total_downloaded_files == 0):
raise Exception("Aborting. No files downloaded")
logging.info("Extracting files ... ")
with zipfile.ZipFile(f"{directory}/formula-1-world-championship-1950-2020.zip", 'r') as zipref:
zipref.extractall(f"{directory}")
for item in list_dir:
if item.endswith(".zip"):
logging.info(f"Removing file: {item}.")
os.remove(os.path.join(directory, item))
except Exception as error:
logging.error(f"Error loading data. Error: {error}")
raise
After downloading data, the next step was to convert data into .parquet files as the "data conversions" defend. I did it in order to save some cloud storage space, as it compresses the file.
def convert_csv_to_parquet(directory):
logging.info("Starting conversion from CSV to parquet files.")
try:
for root, dirs, files in os.walk(f"{directory}"):
for file in files:
p=os.path.join(root,file)
full_path = os.path.abspath(p)
if full_path.endswith('.csv'):
logging.info(f"Reading file {full_path} in CSV format")
table = pyarrowcsv.read_csv(full_path)
logging.info(f"Writing file {full_path} to parquet format")
pyarrowpqt.write_table(table, full_path.replace('.csv', '.parquet'))
except Exception as error:
logging.error(f"Error converting CSV data to parquet. Error: {error}")
raise
After converting all CSV files to parquet format, it was time to upload it to GCP Cloud Storage. The goal was to create a directory structure like "f1-data/raw-files/[year]/[file]" to split data by F1 seasons which happen each civil year.
def upload_data_gcs(directory, bucket_id):
logging.info(f"Starting upload to GCS Bucket: {bucket_id} from directory: {directory} ")
try:
for root, dirs, files in os.walk(f"{directory}"):
for file in files:
p=os.path.join(root,file)
parquet_file_full_path = os.path.abspath(p)
if file.endswith('.parquet'):
logging.info(f"Authenticating in GCS to send parquet_file: {file} ")
client = storage.Client()
bucket = client.bucket(bucket_id)
logging.info("Creating blob.")
blob = bucket.blob(f"f1-data/raw-files/{date.today().year}/{file}")
logging.info(f"Uploading file from location: {parquet_file_full_path} ")
blob.upload_from_filename(parquet_file_full_path)
except Exception as error:
logging.error(f"Error uploading data. Error: {error}")
raise
At this time, i needed to authenticate and upload files using Google Cloud API .
Data Loading
After having the files in GCS, it was time to have them in BigQuery to query it. So, i created a staging dataset with the same exact data that exists in CSV files but in "queryable" format. After this dbt came into play.
def load_staging_files(directory, project_id, dataset_name, bucket_uri):
logging.info(f"Starting loading files for staging in BigQuery.")
try:
client = bigquery.Client()
job_config = bigquery.LoadJobConfig(
source_format=bigquery.SourceFormat.PARQUET,
)
for root, dirs, files in os.walk(f"{directory}"):
for file in files:
if file.endswith('.parquet'):
bucket_file_location = str(bucket_uri) + str(date.today().year) + '/' + str(file)
logging.info(f"Searching file {bucket_file_location} from location: {bucket_uri}")
table_name = f"stg_{Path(f'{file}').stem}"
table_id = f"{project_id}.{dataset_name}.{table_name}"
logging.info(f"Uploading data from table: {table_id}")
load_job = client.load_table_from_uri(
bucket_file_location, table_id, job_config=job_config
)
load_job.result()
destination_table = client.get_table(table_id)
logging.info(f"Loaded: {destination_table.num_rows} rows.")
logging.info(f"Removing all files from {directory} after uploading them to BigQuery.")
for f in os.listdir(directory):
os.remove(os.path.join(directory, f))
except Exception as error:
logging.error(f"Error loading files for stating dataset. Error: {error}")
raise
Data Transformation
This was the most challenging part. The goal was to start using dbt in order to get confortable with the platform. I thought it would help me get the queries done in an easy and mantainable way, and it was really a great help, yet i got the feeling that i wasn't extracting all of it's potential. Even thought it was not easy to start, i managed to get it to work and providing me with the queries i needed. Here's an example of how to extract the winning rate by driver.
{{ config(materialized='table', alias='driver_winning_rate') }}
with driver as (
select forename, surname, driverId from {{ source('src-bq-de-f1-project', 'stg_drivers') }}
),
results as (
select driverId, points, raceId from {{ source('src-bq-de-f1-project', 'stg_results') }}
),
races as (
select year, raceId from {{ source('src-bq-de-f1-project', 'stg_races') }}
),
final as (
select round(sum(q2.number_of_points)/sum(q1.number_of_participations),1) as winning_rate, q1.driver_name, q1.race_year
from (
select concat(driver.forename, ' ', driver.surname) as driver_name, count( distinct results.raceId) as number_of_participations, races.year as race_year, races.raceId as raceId
from results
inner join driver on driver.driverId = results.driverId
inner join races on races.raceId = results.raceId
group by driver_name, race_year, races.raceId
) q1
left join
(select concat(driver.forename, ' ', driver.surname) as driver_name, sum(points) as number_of_points, races.year as race_year , races.raceId as raceId
from results
inner join driver on driver.driverId = results.driverId
inner join races on races.raceId = results.raceId
group by driver_name, race_year, races.raceId
) q2
on q1.driver_name = q2.driver_name and q1.raceId = q2.raceId and q1.race_year = q2.race_year
where q2.number_of_points > 0
group by q1.driver_name, q1.race_year
)
select * from final
The result of the transformations made by dbt were uploaded to a "refined dataset" that feeded the Metabase dashboard.
Data Visualization
After gathering all info, it was time to put it all together in Metabase. It was a learning process, but i think it looks good.
Constructors Dashboard:
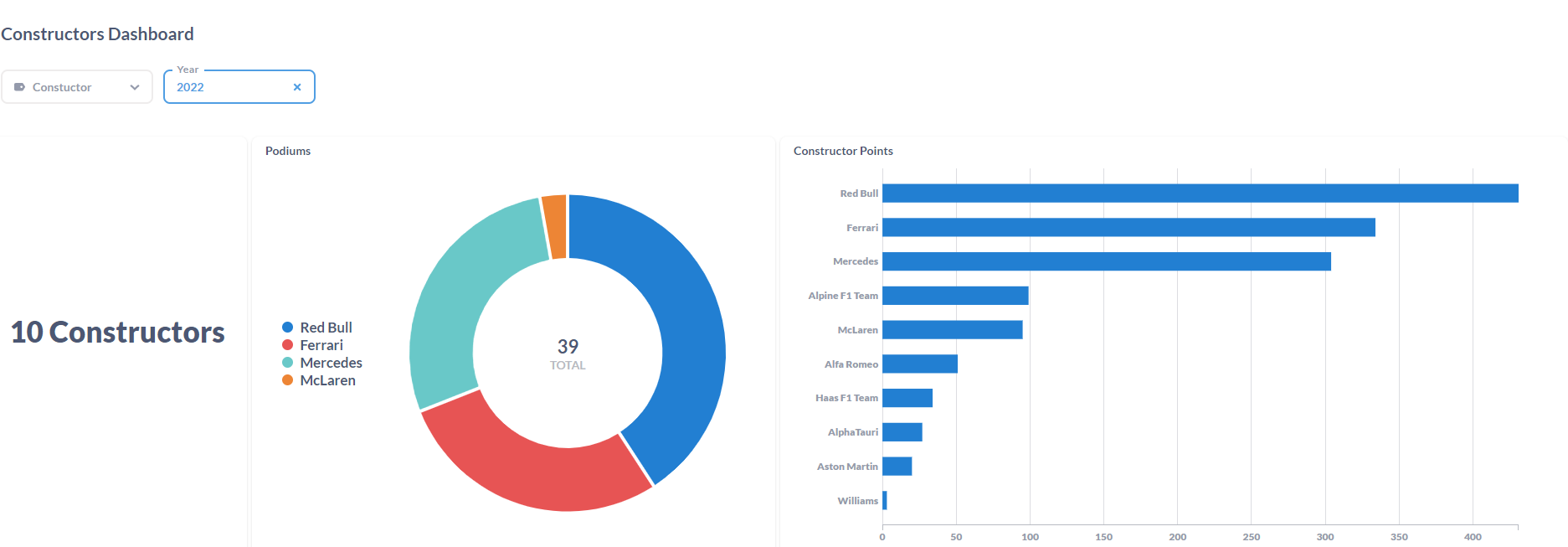
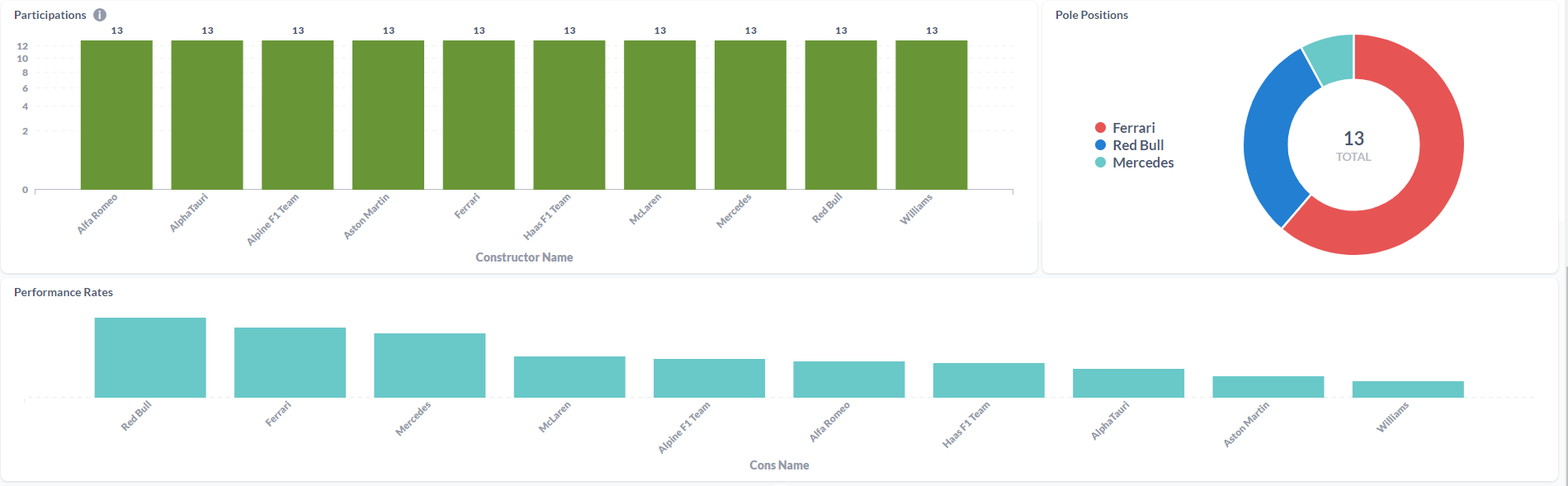
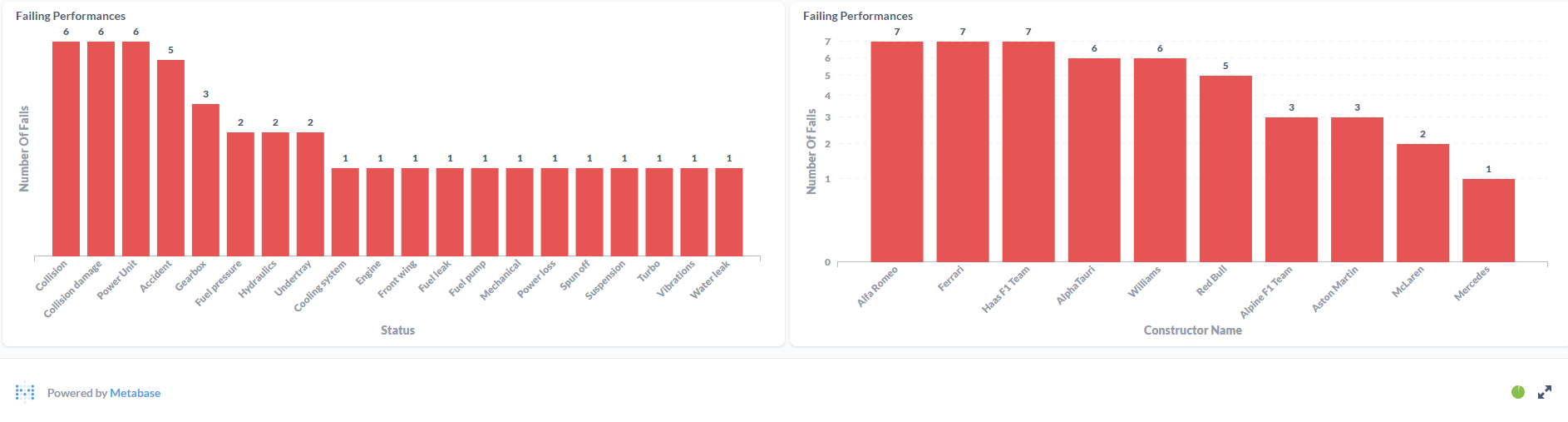
Drivers Dashboard:
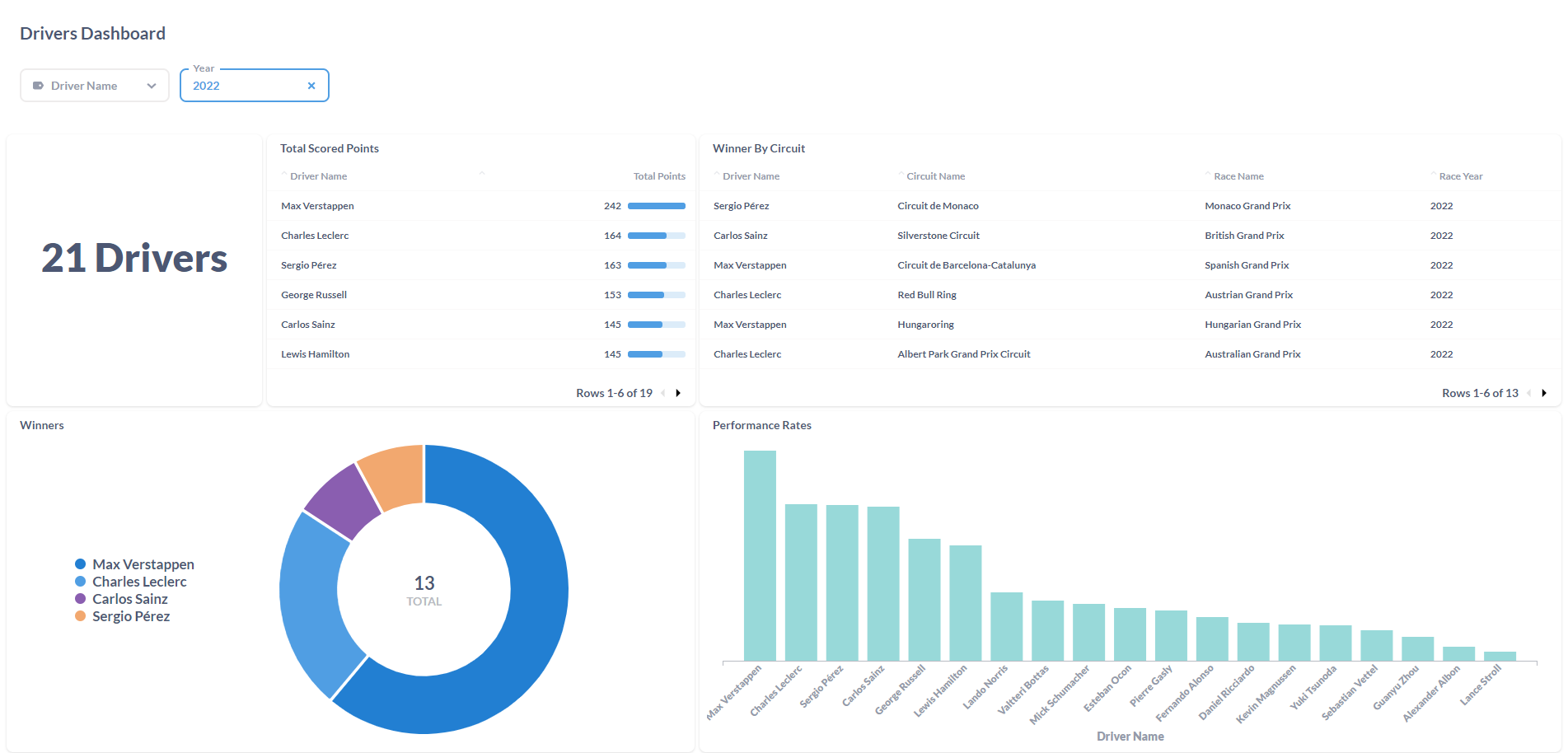
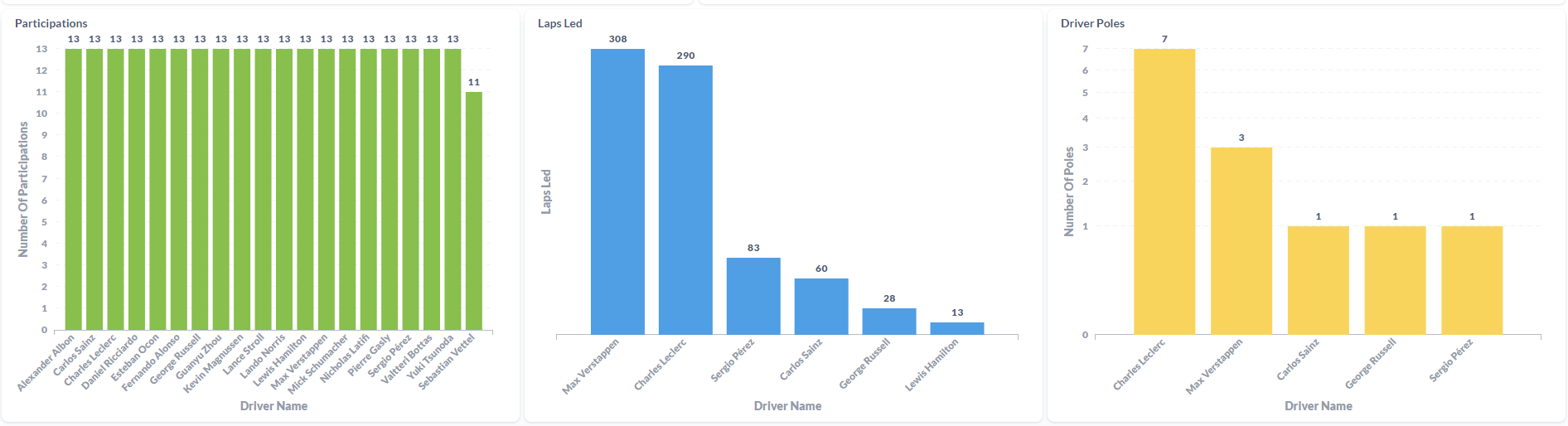
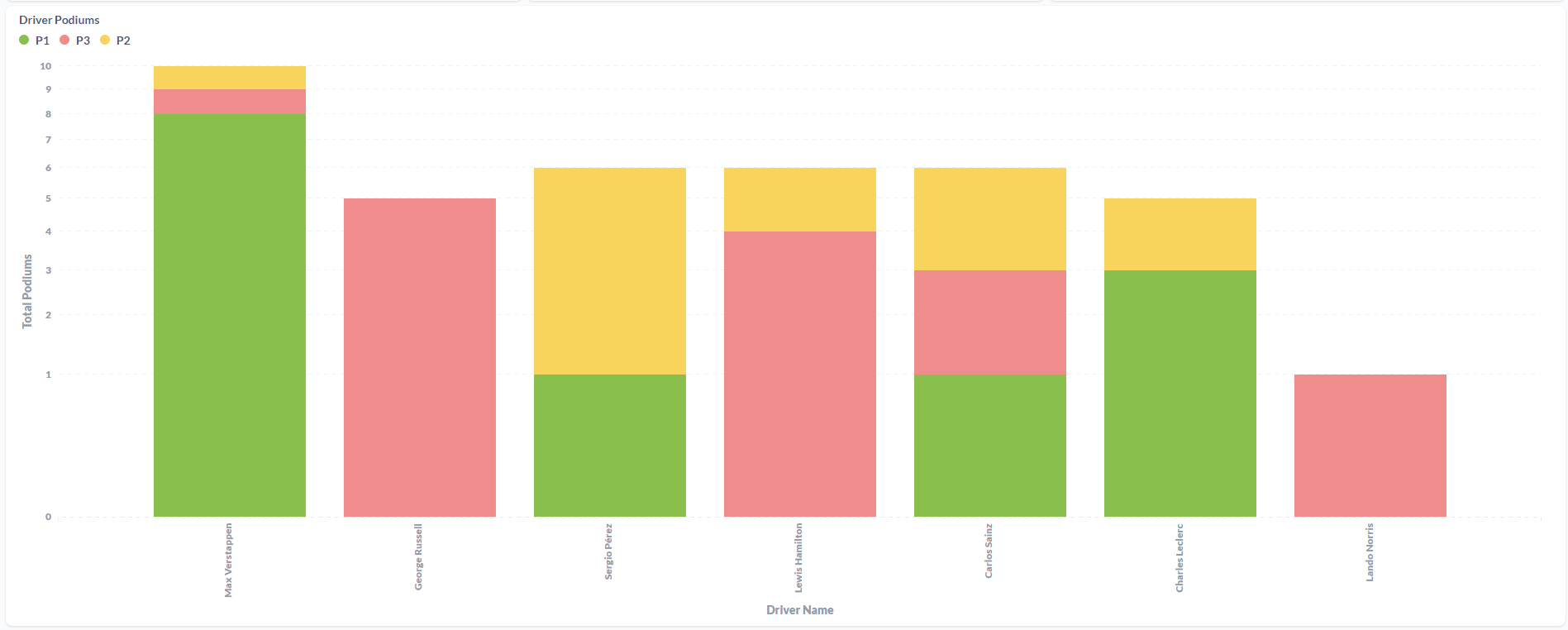
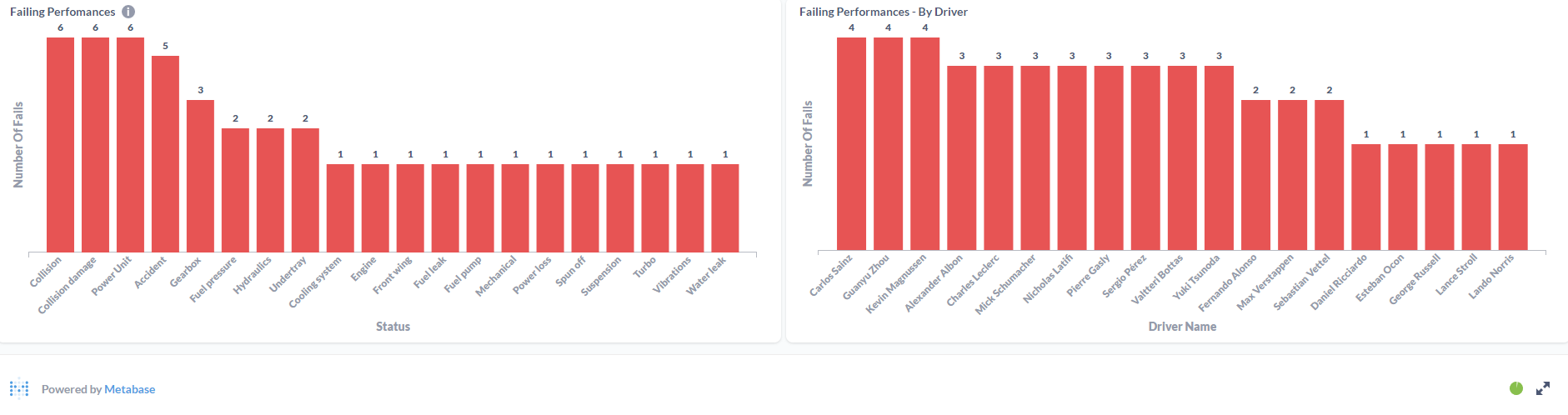
Integrating all technologies
The final step was integrating Airflow, dbt, Metabase under Docker supported by Google Cloud Infrastructure.
Docker The image was built based on airflow official image, built with the help of a Dockerfile.
FROM apache/airflow:2.3.3
ENV AIRFLOW_HOME=/opt/airflow
USER ${AIRFLOW_UID}
#Installing python dependencies
RUN pip install --upgrade pip
RUN pip install kaggle
RUN pip install pyarrow
RUN pip install dbt-bigquery
#Making directories for airflow and kaggle.
RUN mkdir -p /opt/airflow/env_files/kaggle/
RUN mkdir -p /opt/airflow/env_files/google/credentials
RUN mkdir -p /opt/airflow/temp/download/kaggle/
#Copy files to previous created folders
COPY .google/credentials/google_credentials.json /opt/airflow/env_files/google/credentials/
COPY .kaggle/kaggle.json /opt/airflow/env_files/kaggle/
#Set permissions
USER root
RUN chown -R airflow /opt/airflow/env_files/
RUN chown -R airflow /opt/airflow/temp/download/kaggle/
RUN chmod 770 /opt/airflow/temp/download/kaggle/
RUN mkdir -p /opt/dbt/
#Copy dbt files
WORKDIR /opt/dbt/
COPY dbt/dbt_project.yml .
COPY dbt/profiles.yml .
ADD --chown=airflow:root dbt/analyses/ analyses/
ADD --chown=airflow:root dbt/dbt_packages/ dbt_packages/
ADD --chown=airflow:root dbt/logs logs/
ADD --chown=airflow:root dbt/macros macros/
ADD --chown=airflow:root dbt/models models/
ADD --chown=airflow:root dbt/seeds seeds/
ADD --chown=airflow:root dbt/snapshots snapshots/
ADD --chown=airflow:root dbt/target target/
ADD --chown=airflow:root dbt/tests tests/
#Set permissions
RUN chmod -R 770 /opt/dbt/logs
RUN chmod -R 770 /opt/dbt/target
#GCP Specifics
#Ref: https://airflow.apache.org/docs/docker-stack/recipes.html
USER 0
SHELL ["/bin/bash", "-o", "pipefail", "-e", "-u", "-x", "-c"]
ARG CLOUD_SDK_VERSION=322.0.0
ENV GCLOUD_HOME=/home/google-cloud-sdk
ENV PATH="${GCLOUD_HOME}/bin/:${PATH}"
RUN DOWNLOAD_URL="https://dl.google.com/dl/cloudsdk/channels/rapid/downloads/google-cloud-sdk-${CLOUD_SDK_VERSION}-linux-x86_64.tar.gz" \
&& TMP_DIR="$(mktemp -d)" \
&& curl -fL "${DOWNLOAD_URL}" --output "${TMP_DIR}/google-cloud-sdk.tar.gz" \
&& mkdir -p "${GCLOUD_HOME}" \
&& tar xzf "${TMP_DIR}/google-cloud-sdk.tar.gz" -C "${GCLOUD_HOME}" --strip-components=1 \
&& "${GCLOUD_HOME}/install.sh" \
--bash-completion=false \
--path-update=false \
--usage-reporting=false \
--quiet \
&& rm -rf "${TMP_DIR}" \
&& gcloud --version
WORKDIR $AIRFLOW_HOME
USER $AIRFLOW_UID
The containers were managed by docker compose, available in airflow documentation. This docker compose file was changed to include metabase containers.
postgres-metabase:
image: postgres:13
environment:
POSTGRES_USER: <hidden>
POSTGRES_PASSWORD: <hidden>
POSTGRES_DB: <hidden>
volumes:
- /opt/docker/postgres-data:/var/lib/postgresql/data
ports:
- 5433:5432
restart: always
metabase-app:
image: metabase/metabase
restart: always
ports:
- 3000:3000
environment:
MB_DB_TYPE: postgres
MB_DB_DBNAME: <hidden>
MB_DB_PORT: 5432
MB_DB_USER: <hidden>
MB_DB_PASS: <hidden>
MB_DB_HOST: postgres-metabase
depends_on:
- postgres-metabase
links:
- postgres-metabase
Airflow
Were created two DAGs:
- #1 - Get and load all data to Google Cloud Storage
- #2 - Call dbt to perform transformations and get them ready to display information
The DAG #1 connects with Kaggle API, converts data to parquet and upload it to GCS in the first three steps. Meanwhile, it checks if the refined dataset exists and it deletes the existing staging dataset to load new and fresh data. Then, the tasks t5 and t6 it's where the staging dataset it's created again and the upload to BigQuery with the new data it's done. DAG #2 comes to life when the sensor (ExternalTaskSensor) signals that the last task from DAG #1 it's done (t6_load_staging_data) and starts the DAG #2.


Conclusions & Further Steps
This it's not my confort zone, however i am satisfied with the outcome and with all the work behind the shown graphics.
Next steps:
- Create dbt docs to document all tables and columns inside refined dataset
- Create dbt tests for validating the consistency of data
- Review retry mecanisms in these two DAGs in airflow
- Integrate a "live" streaming source of data with help of Kafka.
Due to the costs of having this pipeline running under a GCP VM Instance, the current pipeline is only available if i start the VM manually.